使用特定效应估计器进行效应估计(用于 ACE、中介效应等)#
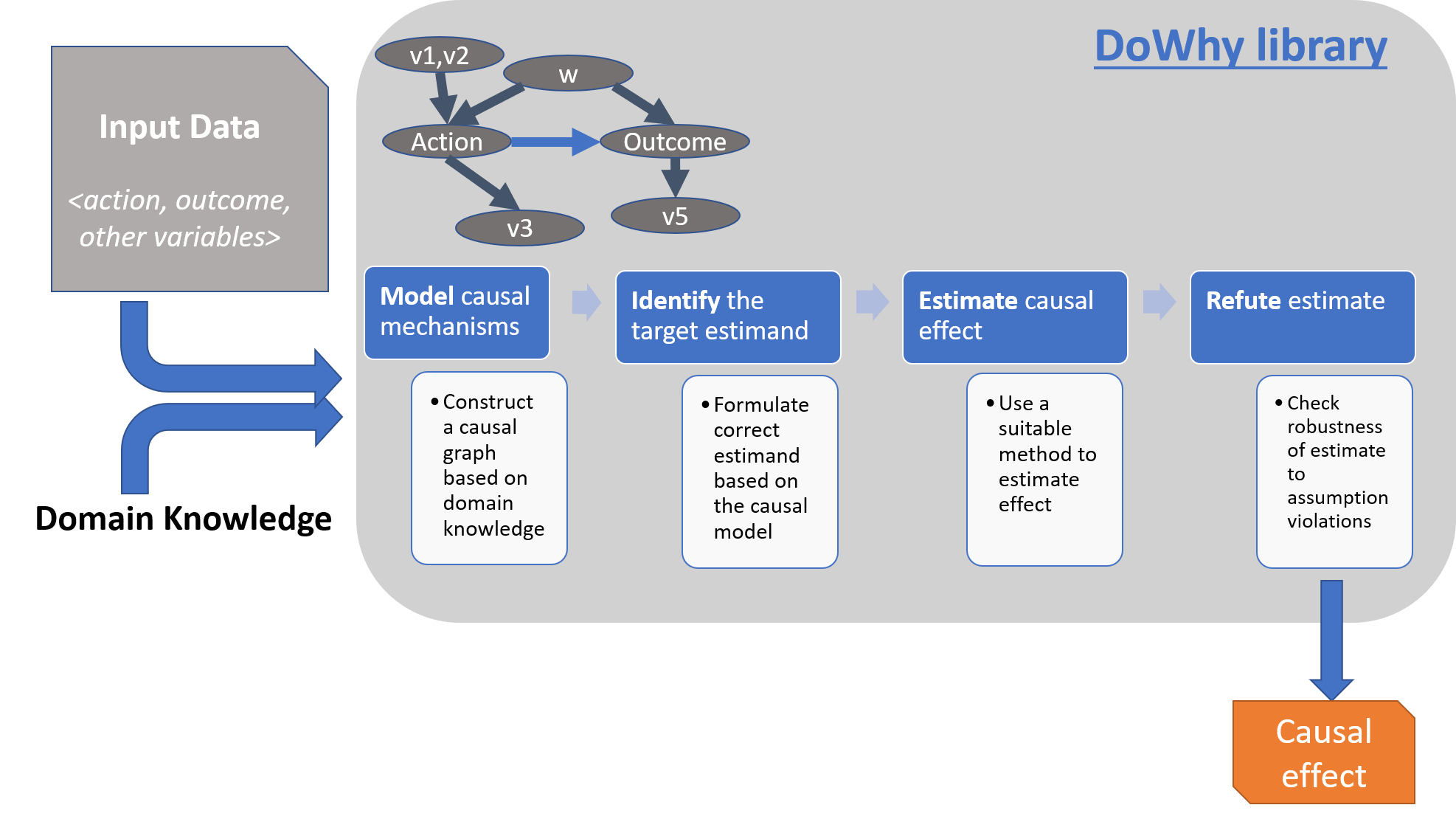
对于效应估计,DoWhy 提供了一个原则性的四步因果推断接口,侧重于明确地建模因果假设并尽可能地验证它们。DoWhy 的关键特性是其最先进的驳斥 API,可以自动测试任何估计方法的因果假设,从而使推断更加健壮且对非专家用户更易于使用。DoWhy 支持通过后门、前门、工具变量和其他识别方法估计平均因果效应,以及通过与 EconML 库集成估计条件效应 (CATE)。
生成样本数据和因果模型#
>>> from dowhy import CausalModel
>>> import dowhy.datasets
>>>
>>> # Load some sample data
>>> data = dowhy.datasets.linear_dataset(
>>> beta=10,
>>> num_common_causes=5,
>>> num_instruments=2,
>>> num_samples=10000,
>>> treatment_is_binary=True)
>>> model = CausalModel(
>>> data=data["df"],
>>> treatment=data["treatment_name"],
>>> outcome=data["outcome_name"],
>>> graph=data["gml_graph"])
在模型下识别目标可估计量#
基于因果图,DoWhy 查找所有可能的方法,根据图模型识别所需的因果效应。它使用基于图的准则和 do-演算来找到潜在的方法,发现可以识别因果效应的表达式。
>>> identified_estimand = model.identify_effect()
支持的识别准则#
后门准则
前门准则
工具变量
中介效应(直接效应和间接效应识别)
不同的 notebook 演示了如何使用这些识别准则。请查看 Simple Backdoor notebook 了解后门准则,以及 Simple IV notebook 了解工具变量准则。
根据已识别的可估计量估计因果效应#
DoWhy 支持基于后门准则和工具变量的方法。它还提供非参数置信区间和置换检验,用于检验所得估计量的统计显著性。
>>> estimate = model.estimate_effect(identified_estimand,
>>> method_name="backdoor.propensity_score_matching")
支持的估计方法#
- 基于估计处理分配的方法
基于倾向得分的分层
倾向得分匹配
逆倾向加权
- 基于估计结果模型的方法
线性回归
广义线性模型
- 基于工具变量方程的方法
二元工具变量/Wald 估计量
两阶段最小二乘法
回归不连续设计
- 前门准则和一般中介效应方法
两阶段线性回归
使用这些方法的示例可在 Estimation methods notebook 中找到。
在 DoWhy 中使用 EconML 和 CausalML 估计方法#
使用 DoWhy 调用外部估计方法非常容易。目前我们支持与 EconML 和 CausalML 软件包集成。这里有一个使用 EconML 的双重机器学习估计器估计条件处理效应的示例。
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LassoCV
from sklearn.ensemble import GradientBoostingRegressor
dml_estimate = model.estimate_effect(identified_estimand, method_name="backdoor.econml.dml.DML",
control_value = 0,
treatment_value = 1,
target_units = lambda df: df["X0"]>1,
confidence_intervals=False,
method_params={
"init_params":{'model_y':GradientBoostingRegressor(),
'model_t': GradientBoostingRegressor(),
'model_final':LassoCV(),
'featurizer':PolynomialFeatures(degree=1, include_bias=True)},
"fit_params":{}}
)
更多示例可在 Conditional Treatment Effects with DoWhy notebook 中找到。
驳斥所得估计量#
能够使用多种驳斥方法来验证因果估计器的效应估计量是使用 DoWhy 的一个关键优势。
>>> refute_results = model.refute_estimate(identified_estimand, estimate,
>>> method_name="random_common_cause")
支持的驳斥方法#
添加随机共同原因:在我们将一个独立的随机变量作为共同原因添加到数据集中后,估计方法是否会改变其估计值?(提示:不应该改变)
安慰剂处理:当我们用一个独立的随机变量替换真实的处理变量时,估计的因果效应会发生什么?(提示:效应应该趋于零)
虚拟结果:当我们用一个独立的随机变量替换真实的结果变量时,估计的因果效应会发生什么?(提示:效应应该趋于零)
模拟结果:当我们用基于已知数据生成过程(最接近给定数据集)的模拟数据集替换原始数据集时,估计的因果效应会发生什么?(提示:应该与数据生成过程中的效应参数一致)
添加未观测到的共同原因:当我们向数据集中添加一个与处理变量和结果变量相关的额外共同原因(混杂因素)时,效应估计量有多敏感?(提示:不应该太敏感)
数据子集验证:当我们用随机选择的子集替换给定数据集时,估计的效应是否会显著改变?(提示:不应该改变)
Bootstrap 验证:当我们用从相同数据集中 bootstrap 抽取的样本替换给定数据集时,估计的效应是否会显著改变?(提示:不应该改变)
使用驳斥方法的示例可在 Refutations notebook 中找到。有关使用基于用户提供或学习的数据生成过程的模拟数据集进行高级驳斥的示例,请查看 Dummy Outcome Refuter notebook。作为一个实际示例,此 notebook 展示了驳斥方法在评估婴儿健康与发展计划 (IHDP) 和 Lalonde 数据集效应估计器方面的应用。
与其他软件包的比较#
DoWhy 的效应推断 API 涵盖了因果推断的所有四个步骤
使用假设建模因果推断问题。
在这些假设下识别因果效应的表达式(“因果可估计量”)。
使用统计方法(如匹配或工具变量)估计该表达式。
最后,使用各种稳健性检查验证估计值的有效性。
这个工作流程由 DoWhy 中的四个关键动词概括
model (建模)
identify (识别)
estimate (估计)
refute (驳斥)
使用这些动词,DoWhy 实现了一个因果推断引擎,可以支持各种方法。model 将先验知识编码为形式化的因果图,identify 使用基于图的方法来识别因果效应,estimate 使用统计方法来估计已识别的可估计量,最后 refute 尝试通过测试对假设的稳健性来驳斥所得的估计值。
主要区别:因果假设作为一等公民#
由于 DoWhy 侧重于因果分析的完整流程(而不仅仅是单个步骤),因此与现有的因果推断软件相比有三个不同之处。
- 明确的识别假设
假设在 DoWhy 中是一等公民。
每个分析都始于构建因果模型。假设可以图形化地查看,也可以用条件独立性语句来表达。在可能的情况下,DoWhy 还可以使用观测数据自动测试已声明的假设。
- 识别与估计的分离
识别是因果问题。估计仅仅是统计问题。
DoWhy 尊重这一界限,并将其分开处理。这使得因果推断的重点放在识别上,并允许使用任何可用的统计估计器来估计目标可估计量。此外,对于一个已识别的可估计量,可以使用多种估计方法,反之亦然。
- 自动化稳健性检查
当关键的识别假设可能不满足时会发生什么?
因果分析中最关键且经常被忽略的部分是检查估计值对未经证实的假设的稳健性。DoWhy 使自动对所得估计值运行敏感性和稳健性检查变得容易。
最后,DoWhy 易于扩展,允许四个动词的其他实现并存(例如,我们支持来自 EconML 和 CausalML 库的 estimation 动词的实现)。这四个动词相互独立,因此它们的实现可以以任何方式组合。