估计因果效应#
变量 $A$ 对 $Y$ 的因果效应定义为 $A$ 变化导致 $Y$ 的预期变化。使用 do-calculus 记号,平均因果效应可以写为 \(E[Y|do(A)]\)。有时,我们只关注子群体的因果效应,或者想比较不同子群体的因果效应。在这种情况下,给定一组协变量 $X$,我们可以估计条件平均因果效应 (CACE),即 \(E[Y|do(A), X]\)。
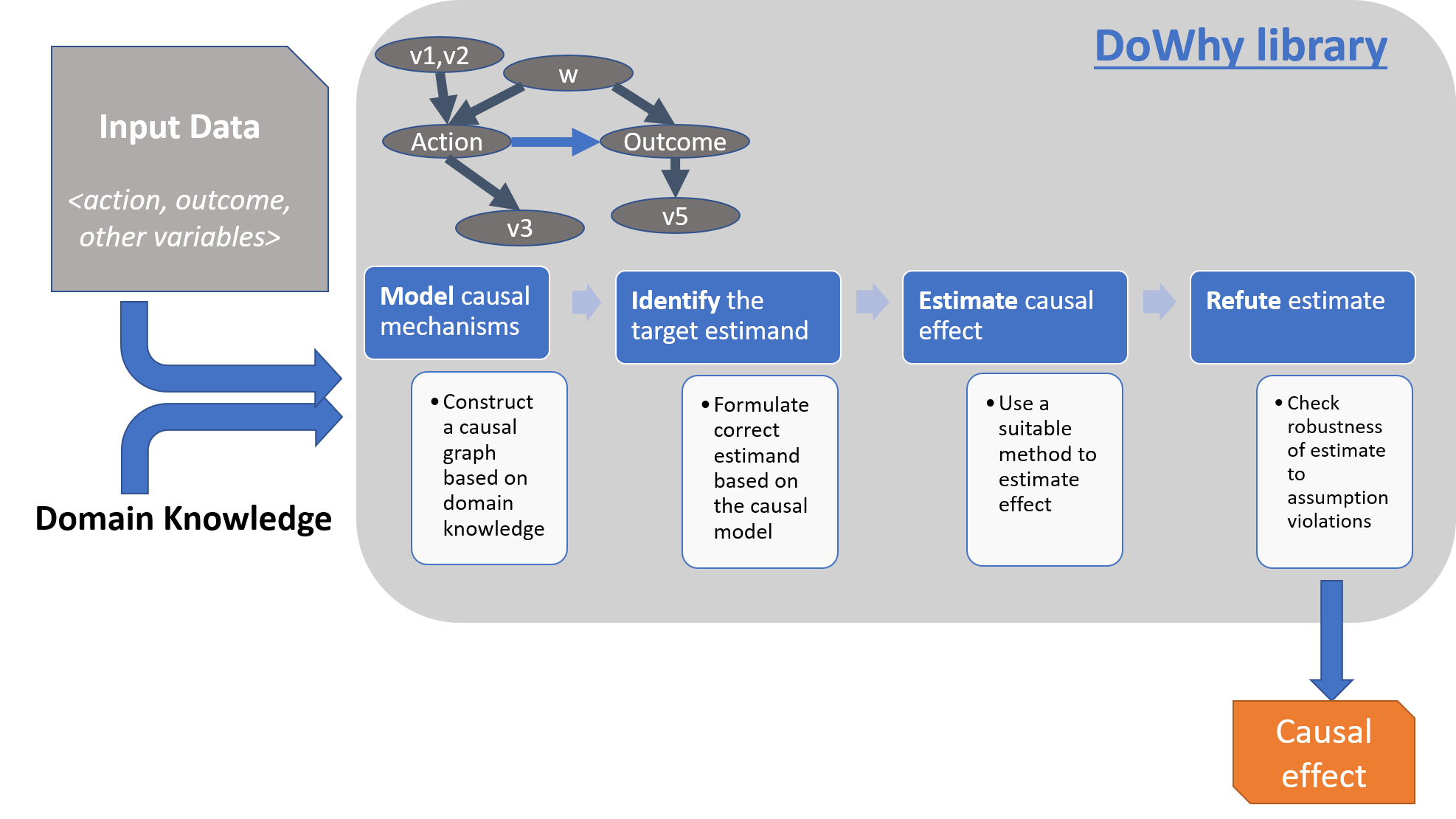
估计因果效应需要四个步骤
使用假设对因果推断问题进行建模。
在这些假设下识别因果效应的表达式(“因果可估计量”)。
使用匹配法或工具变量等统计方法估计该表达式。
最后,使用多种稳健性检验来验证估计的有效性。
DoWhy 通过四个关键动词捕获了这一工作流程
建模 (CausalModel 或 graph)
识别 (identify_effect)
估计 (estimate_effect)
驳斥 (refute_estimate)
使用这些动词,DoWhy 实现了一个支持多种方法的因果效应估计 API。model 将先验知识编码为正式的因果图,identify 使用基于图的方法识别因果效应,estimate 使用统计方法估计识别出的可估计量,最后 refute 尝试通过测试对假设的稳健性来驳斥获得的估计结果。因此,构建因果图后,估计因果效应的下一步是识别该效应是否可以从现有数据中估计。换句话说,在考虑估计算法之前,确定识别策略非常重要。DoWhy 支持以下识别算法
后门
前门
工具变量
ID 算法
一旦因果效应被识别,我们可以选择与识别策略兼容的估计方法。对于估计平均因果效应,DoWhy 支持以下方法。
- 基于混杂变量值匹配的方法
基于距离的匹配 (
DistanceMatchingEstimator)
- 基于估计处理分配的方法
基于倾向分的分层 (
PropensityScoreStratificationEstimator)倾向分匹配 (
PropensityScoreMatchingEstimator)逆倾向加权 (
PropensityScoreWeightingEstimator)
- 基于估计结果模型的方法
线性回归 (
LinearRegressionEstimator)广义线性模型,包括逻辑回归 (
GeneralizedLinearModelEstimator)
- 基于工具变量方程的方法
二元工具/Wald 估计量 (
InstrumentalVariableEstimator)回归不连续 (
RegressionDiscontinuityEstimator)
- 前门准则和中介分析方法
两阶段线性回归 (
TwoStageRegressionEstimator)
对于估计条件平均因果效应,DoWhy 支持调用 EconML 方法。有关 EconML 的更多详细信息,请查看其文档。如果结果 Y 的数据生成过程可以近似为线性函数,您也可以使用线性回归方法进行 CACE 估计。
相关笔记本请参见示例笔记本