定制因果机制分配#
在基于 GCM 的推断中,拟合意味着我们从数据中学习图中变量的生成模型。在将变量拟合到数据之前,因果图中的每个节点都需要一个生成因果模型,或称“因果机制”。在本节中,我们将深入探讨如何使用此功能。
为了理解这一点,让我们再次回顾概率因果模型 (PCM) 的心智模型
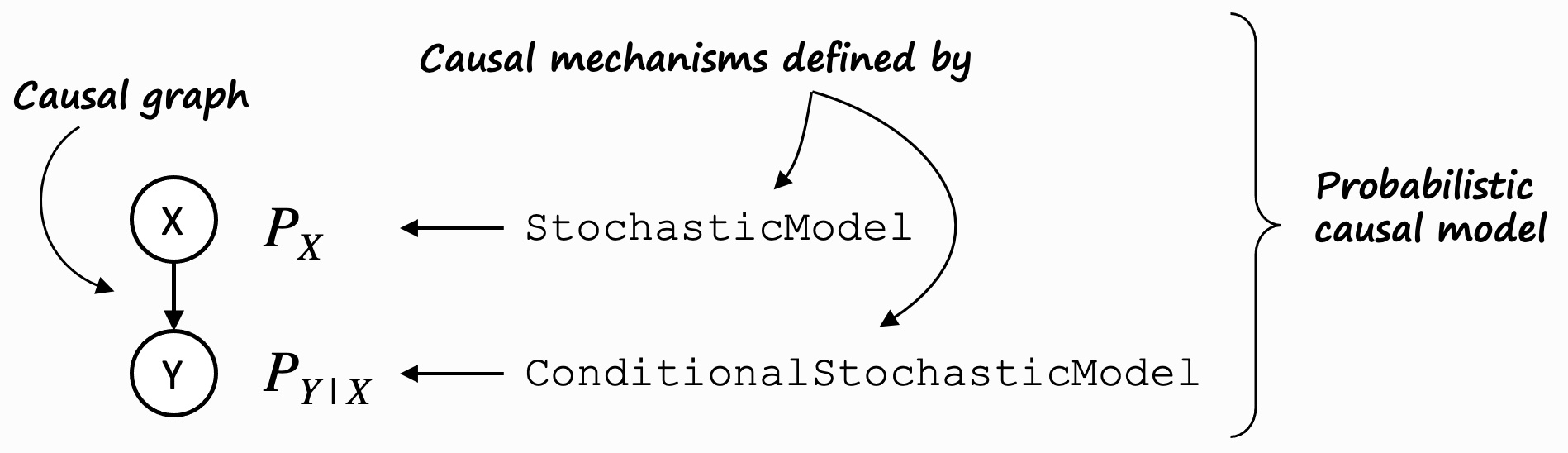
左侧显示了一个简单的因果图 \(X \rightarrow Y\)。\(X\) 是一个所谓的根节点(它没有父节点),\(Y\) 是一个非根节点(它有父节点)。我们从根本上区分这两种类型的节点。
对于根节点,例如 \(X\),其分布 \(P_x\) 使用随机模型进行建模。非根节点,例如 \(Y\),使用条件随机模型进行建模。DoWhy 的 gcm 软件包为两者定义了相应的接口,即 StochasticModel 和 ConditionalStochasticModel。
gcm 软件包还提供了即用型实现,例如 ScipyDistribution 或 BayesianGaussianMixtureDistribution 用于 StochasticModel,以及 AdditiveNoiseModel 用于 ConditionalStochasticModel。
了解了这些,我们现在可以根据需要手动为节点分配因果模型。假设我们从领域知识中得知,我们的根节点 X 服从正态分布。在这种情况下,我们可以明确地分配它
>>> from scipy.stats import norm
>>> import networkx as nx
>>> from dowhy import gcm
>>>
>>> causal_model = gcm.ProbabilisticCausalModel(nx.DiGraph([('X', 'Y')]))
>>> causal_model.set_causal_mechanism('X', gcm.ScipyDistribution(norm))
对于非根节点 Y,让我们使用加性噪声模型 (ANM),由 AdditiveNoiseModel 类表示。它具有以下形式的结构赋值:\(Y := f(X) + N\)。这里,\(f\) 是一个确定性预测函数,而 \(N\) 是一个噪声项。让我们将这一切整合起来
>>> causal_model.set_causal_mechanism('Y',
>>> gcm.AdditiveNoiseModel(prediction_model=gcm.ml.create_linear_regressor(),
>>> noise_model=gcm.ScipyDistribution(norm)))
这里比较有趣的部分是 prediction_model,它对应于上面的函数 \(f\)。这个预测模型必须满足 PredictionModel 定义的契约,即它必须实现以下方法
def fit(self, X: np.ndarray, Y: np.ndarray) -> None: ...
def predict(self, X: np.ndarray) -> np.ndarray: ...
这个接口与许多机器学习库(例如 Scikit Learn)中的模型接口非常相似。实际上,gcm 软件包提供了多个适配器类,使像 Scikit Learn 这样的库能够互操作。
现在我们已经为因果图中的每个节点关联了一个数据生成过程,接下来准备训练数据。
>>> import numpy as np, pandas as pd
>>> X = np.random.normal(loc=0, scale=1, size=1000)
>>> Y = 2*X + np.random.normal(loc=0, scale=1, size=1000)
>>> data = pd.DataFrame(data=dict(X=X, Y=Y))
最后,我们可以从训练数据中学习这些因果模型的参数。
>>> gcm.fit(causal_model, data)
causal_model 现在可以用于各种类型的因果查询,如 执行因果任务 中所述。
注意
如上所述,DoWhy 有一个封装类,开箱即用地支持 scikit learn 模型。例如
>>> from sklearn.ensemble import RandomForestRegressor
>>> causal_model.set_causal_mechanism('Y', gcm.AdditiveNoiseModel(gcm.ml.SklearnRegressionModel(RandomForestRegressor)))
将使用 sklearn 包中的 RandomForestRegressor 而不是 LinearRegressor。
使用真实模型#
在某些场景中,真实模型可能已知,应该直接使用。假设我们知道我们的关系是线性的,系数为 \(\alpha = 2\) 和 \(\beta = 3\)。让我们利用这些知识创建一个实现 PredictionModel 接口的自定义预测模型
>>> import dowhy.gcm.ml.prediction_model
>>>
>>> class MyCustomModel(gcm.ml.PredictionModel):
>>> def __init__(self, coefficient):
>>> self.coefficient = coefficient
>>>
>>> def fit(self, X, Y):
>>> # Nothing to fit here, since we know the ground truth.
>>> pass
>>>
>>> def predict(self, X):
>>> return self.coefficient * X
>>>
>>> def clone(self):
>>> return MyCustomModel(self.coefficient)
现在我们可以将其用于我们的 ANM 中
>>> causal_model.set_causal_mechanism('Y', gcm.AdditiveNoiseModel(MyCustomModel(2)))
>>> gcm.fit(causal_model, data)
注意
重要提示:当调用需要因果图的函数或算法时,DoWhy GCM 会根据输入特征的字母顺序在内部进行排序。例如,在上面的 MyCustomModel 情况下,如果输入特征的名称是 ‘X2’ 和 ‘X1’,则模型应期望第一个输入是 ‘X1’,第二个输入是 ‘X2’。
从方程创建因果模型 (GCM)#
在上一节中,我们了解了如何为节点创建和使用真实模型。现在,在几乎所有节点的真实情况都已知并且我们想要从中创建一个自定义因果模型而无需编写大量代码的情况下,从方程创建图形因果模型(GCM)就成为了一个强大的实用工具,通过定义节点之间的关系来实现因果模型的生成。当节点间关系已知时,此功能非常宝贵,提供了一种构建自定义因果模型的方法。在本节中,我们将深入探讨如何使用此功能。
- 定义方程
此功能支持三种方程格式:根节点方程、非根节点方程以及未知因果关系的方程。
- 每种节点类型的结构
- 根节点
<节点名称> = \(N_i\)
- 非根节点
<节点名称> = \(f_i(PA_i) + N_i\)
- 节点与其父节点的未知关系
<节点名称> -> PA_i,…
注意,在上面的结构中,\(N_i\) 是噪声模型,而 \(f_i(PA_i)\) 符号是函数因果模型,或者简单地说是一个定义当前节点与其父节点之间关系的函数。
根节点方程定义了根节点的关系,指定了一个噪声模型。非根节点方程通过包含一个涉及其他节点和噪声模型的函数表达式来扩展这一点。当节点之间的确切关系未知,仅指定边时,使用未知因果模型方程。
- 定义噪声模型(N)
- 噪声模型包括经验的 (empirical)、贝叶斯高斯混合的 (Bayesian Gaussian mixture)、参数化的 (parametric) 以及 scipy.stats 库中的选项。让我们详细看看每个选项 -
empirical(): 随机模型类的一个实现。
bayesiangaussianmixture(): 随机模型类的一个实现。
parametric(): 当您希望系统为数据找到最佳连续分布时使用它。
<scipy_function>(): 您可以指定 scipy.stats 库中定义的连续分布函数。
- 定义函数因果模型(F(X))
子节点和父节点之间的关系可以在一个表达式中定义,该表达式支持 numpy 库中的几乎所有算术运算和函数
- 节点的未定义/未知关系
当子节点和父节点之间的关系未知时,用户可以按以下示例定义此类节点 -
\(X_i -> PA_i, PA_i\)
- 示例
用户可以提供一个包含表示节点之间因果关系的方程的字符串。
from dowhy import gcm
from dowhy.utils import plot
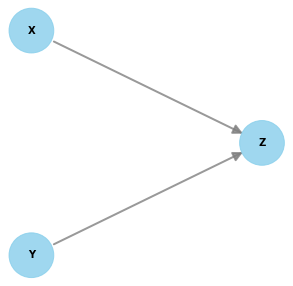
scm = """
X = empirical()
Y = norm(loc=0, scale=1)
Z = 12 * X + log(abs(Y)) + norm(loc=0, scale=1)
"""
causal_model = gcm.create_causal_model_from_equations(scm)
print(plot(causal_model.graph))
注意
此功能会净化输入方程,以防止安全漏洞。
节点命名目前受限于 Python 变量命名规则,这意味着节点名称只能包含字母、数字(不能作为开头)和下划线 ‘_’ 字符。