探索酒店预订取消的原因#

我们考虑哪些因素导致酒店预订被取消。本分析基于 Antonio, Almeida 和 Nunes (2019) 的酒店预订数据集。该数据集在 GitHub 上位于 rfordatascience/tidytuesday。
预订取消可能有多种原因。客户可能要求了无法提供的服务(例如,停车场),客户后来可能发现酒店不符合他们的要求,或者客户可能仅仅取消了整个行程。其中一些因素,如停车场,是酒店可以采取行动的,而另一些因素,如行程取消,则超出酒店的控制范围。无论如何,我们都希望更好地了解这些因素中哪些会导致预订取消。
找出真相的黄金标准是使用实验,例如**随机对照试验**,其中每个客户被随机分配到两个类别之一,即每个客户要么被分配一个停车位,要么不分配。然而,这样的实验可能成本过高,在某些情况下也可能不道德(例如,如果人们知道酒店是随机分配给不同服务水平的,酒店的声誉就会开始受损)。
我们能否仅使用观测数据或过去收集的数据来回答我们的问题呢?
[1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import dowhy
数据描述#
读者可在此快速浏览特征及其描述:rfordatascience/tidytuesday
[2]:
dataset = pd.read_csv('https://raw.githubusercontent.com/Sid-darthvader/DoWhy-The-Causal-Story-Behind-Hotel-Booking-Cancellations/master/hotel_bookings.csv')
dataset.head()
[2]:
| hotel | is_canceled | lead_time | arrival_date_year | arrival_date_month | arrival_date_week_number | arrival_date_day_of_month | stays_in_weekend_nights | stays_in_week_nights | adults | ... | deposit_type | agent | company | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | reservation_status | reservation_status_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Resort Hotel | 0 | 342 | 2015 | July | 27 | 1 | 0 | 0 | 2 | ... | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 1 | Resort Hotel | 0 | 737 | 2015 | July | 27 | 1 | 0 | 0 | 2 | ... | No Deposit | NaN | NaN | 0 | Transient | 0.0 | 0 | 0 | Check-Out | 2015-07-01 |
| 2 | Resort Hotel | 0 | 7 | 2015 | July | 27 | 1 | 0 | 1 | 1 | ... | No Deposit | NaN | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 3 | Resort Hotel | 0 | 13 | 2015 | July | 27 | 1 | 0 | 1 | 1 | ... | No Deposit | 304.0 | NaN | 0 | Transient | 75.0 | 0 | 0 | Check-Out | 2015-07-02 |
| 4 | Resort Hotel | 0 | 14 | 2015 | July | 27 | 1 | 0 | 2 | 2 | ... | No Deposit | 240.0 | NaN | 0 | Transient | 98.0 | 0 | 1 | Check-Out | 2015-07-03 |
5 行 × 32 列
[3]:
dataset.columns
[3]:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'stays_in_weekend_nights',
'stays_in_week_nights', 'adults', 'children', 'babies', 'meal',
'country', 'market_segment', 'distribution_channel',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'reserved_room_type',
'assigned_room_type', 'booking_changes', 'deposit_type', 'agent',
'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date'],
dtype='object')
特征工程#
让我们创建一些新的有意义的特征,以降低数据集的维度。- **总入住天数 (Total Stay)** = stays_in_weekend_nights + stays_in_week_nights - **入住人数 (Guests)** = adults + children + babies - **分配不同房间 (Different_room_assigned)** = 如果 reserved_room_type 和 assigned_room_type 不同则为 1,否则为 0。
[4]:
# Total stay in nights
dataset['total_stay'] = dataset['stays_in_week_nights']+dataset['stays_in_weekend_nights']
# Total number of guests
dataset['guests'] = dataset['adults']+dataset['children'] +dataset['babies']
# Creating the different_room_assigned feature
dataset['different_room_assigned']=0
slice_indices =dataset['reserved_room_type']!=dataset['assigned_room_type']
dataset.loc[slice_indices,'different_room_assigned']=1
# Deleting older features
dataset = dataset.drop(['stays_in_week_nights','stays_in_weekend_nights','adults','children','babies'
,'reserved_room_type','assigned_room_type'],axis=1)
dataset.columns
[4]:
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'meal', 'country', 'market_segment',
'distribution_channel', 'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'booking_changes', 'deposit_type',
'agent', 'company', 'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'reservation_status', 'reservation_status_date', 'total_stay', 'guests',
'different_room_assigned'],
dtype='object')
我们还移除了其他包含 NULL 值或具有太多唯一值(例如,agent ID)的列。我们还将 country 列的缺失值用出现次数最多的国家填充。我们移除了 distribution_channel,因为它与 market_segment 的重叠度很高。
[5]:
dataset.isnull().sum() # Country,Agent,Company contain 488,16340,112593 missing entries
dataset = dataset.drop(['agent','company'],axis=1)
# Replacing missing countries with most freqently occuring countries
dataset['country']= dataset['country'].fillna(dataset['country'].mode()[0])
[6]:
dataset = dataset.drop(['reservation_status','reservation_status_date','arrival_date_day_of_month'],axis=1)
dataset = dataset.drop(['arrival_date_year'],axis=1)
dataset = dataset.drop(['distribution_channel'], axis=1)
[7]:
# Replacing 1 by True and 0 by False for the experiment and outcome variables
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(1,True)
dataset['different_room_assigned']= dataset['different_room_assigned'].replace(0,False)
dataset['is_canceled']= dataset['is_canceled'].replace(1,True)
dataset['is_canceled']= dataset['is_canceled'].replace(0,False)
dataset.dropna(inplace=True)
print(dataset.columns)
dataset.iloc[:, 5:20].head(100)
Index(['hotel', 'is_canceled', 'lead_time', 'arrival_date_month',
'arrival_date_week_number', 'meal', 'country', 'market_segment',
'is_repeated_guest', 'previous_cancellations',
'previous_bookings_not_canceled', 'booking_changes', 'deposit_type',
'days_in_waiting_list', 'customer_type', 'adr',
'required_car_parking_spaces', 'total_of_special_requests',
'total_stay', 'guests', 'different_room_assigned'],
dtype='object')
[7]:
| meal | country | market_segment | is_repeated_guest | previous_cancellations | previous_bookings_not_canceled | booking_changes | deposit_type | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | total_stay | guests | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | BB | PRT | Direct | 0 | 0 | 0 | 3 | No Deposit | 0 | Transient | 0.00 | 0 | 0 | 0 | 2.0 |
| 1 | BB | PRT | Direct | 0 | 0 | 0 | 4 | No Deposit | 0 | Transient | 0.00 | 0 | 0 | 0 | 2.0 |
| 2 | BB | GBR | Direct | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 75.00 | 0 | 0 | 1 | 1.0 |
| 3 | BB | GBR | Corporate | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 75.00 | 0 | 0 | 1 | 1.0 |
| 4 | BB | GBR | Online TA | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 98.00 | 0 | 1 | 2 | 2.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | BB | PRT | Online TA | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 73.80 | 0 | 1 | 2 | 2.0 |
| 96 | BB | PRT | Online TA | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 117.00 | 0 | 1 | 7 | 2.0 |
| 97 | HB | ESP | Offline TA/TO | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 196.54 | 0 | 1 | 7 | 3.0 |
| 98 | BB | PRT | Online TA | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 99.30 | 1 | 2 | 7 | 3.0 |
| 99 | BB | DEU | Direct | 0 | 0 | 0 | 0 | No Deposit | 0 | Transient | 90.95 | 0 | 0 | 7 | 2.0 |
100 行 × 15 列
[8]:
dataset = dataset[dataset.deposit_type=="No Deposit"]
dataset.groupby(['deposit_type','is_canceled']).count()
[8]:
| hotel | lead_time | arrival_date_month | arrival_date_week_number | meal | country | market_segment | is_repeated_guest | previous_cancellations | previous_bookings_not_canceled | booking_changes | days_in_waiting_list | customer_type | adr | required_car_parking_spaces | total_of_special_requests | total_stay | guests | different_room_assigned | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| deposit_type | is_canceled | |||||||||||||||||||
| No Deposit | False | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 | 74947 |
| True | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 | 29690 |
[9]:
dataset_copy = dataset.copy(deep=True)
计算预期计数#
由于取消次数和分配不同房间的次数严重不平衡,我们首先随机选择 1000 个观测值,看看变量“is_cancelled”和“different_room_assigned”取相同值的情况有多少。然后将整个过程重复 10000 次,预期计数接近 50%(即这两个变量随机取相同值的概率)。所以从统计学上讲,现阶段我们没有明确的结论。因此,分配与客户之前预订时预留的房间类型不同的房间,可能导致也可能不导致他/她取消该预订。
[10]:
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset.sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[10]:
现在我们考虑没有预订更改的情况,并重新计算预期计数。
[11]:
# Expected Count when there are no booking changes
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]==0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[11]:
在第二种情况下,我们考虑有预订更改(>0)的情况,并重新计算预期计数。
[12]:
# Expected Count when there are booking changes = 66.4%
counts_sum=0
for i in range(1,10000):
counts_i = 0
rdf = dataset[dataset["booking_changes"]>0].sample(1000)
counts_i = rdf[rdf["is_canceled"]== rdf["different_room_assigned"]].shape[0]
counts_sum+= counts_i
counts_sum/10000
[12]:
当预订更改数量非零时,肯定发生了一些变化。这给我们一个提示,**预订更改**可能正在影响房间取消。
但是,**预订更改**是唯一的混杂变量吗?如果存在一些我们数据中没有捕捉到的未观测混杂因素(特征),我们是否仍然能够做出与之前相同的声明?
使用 DoWhy 估计因果效应#
步骤 1. 创建因果图#
使用假设将您对预测建模问题的先验知识表示为 CI 图。不用担心,您现阶段不需要指定完整的图。即使是部分图也足够了,其余的可以由 *DoWhy* 推断出来 ;-)
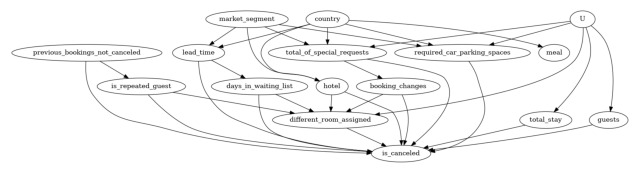
以下是将假设转化为因果图的列表:-
**市场细分**有 2 个级别,“TA”指“旅行社”,“TO”指“旅游运营商”,因此它应该影响提前预订时间(即预订和入住之间的天数)。
**国家**也会影响一个人是否提前预订(因此有更长的**提前预订时间**)以及一个人会偏好哪种**餐食**。
**提前预订时间**肯定会影响**等待天数**(预订越晚,找到预订的机会越少)。此外,更长的**提前预订时间**也可能导致**取消**。
**等待天数**、总入住天数(**总入住天数**)和**入住人数**可能会影响预订是否被取消或保留。
**以前未取消的预订**会影响客户是否为重复客户。此外,这两个变量都会影响预订是否被**取消**(例如,一个过去保留了 5 次预订的客户更有可能保留这次预订。同样,一个已经取消过预订的人更有可能重复同样的行为)。
**预订更改**会影响客户是否被分配**不同房间**,这可能也会导致**取消**。
最后,**预订更改**作为唯一影响**处理**和**结果**的变量,这种情况极不可能发生,并且可能存在一些**未观测混杂因素**,我们数据中没有捕捉到关于它们的信息。
[13]:
import pygraphviz
causal_graph = """digraph {
different_room_assigned[label="Different Room Assigned"];
is_canceled[label="Booking Cancelled"];
booking_changes[label="Booking Changes"];
previous_bookings_not_canceled[label="Previous Booking Retentions"];
days_in_waiting_list[label="Days in Waitlist"];
lead_time[label="Lead Time"];
market_segment[label="Market Segment"];
country[label="Country"];
U[label="Unobserved Confounders",observed="no"];
is_repeated_guest;
total_stay;
guests;
meal;
hotel;
U->{different_room_assigned,required_car_parking_spaces,guests,total_stay,total_of_special_requests};
market_segment -> lead_time;
lead_time->is_canceled; country -> lead_time;
different_room_assigned -> is_canceled;
country->meal;
lead_time -> days_in_waiting_list;
days_in_waiting_list ->{is_canceled,different_room_assigned};
previous_bookings_not_canceled -> is_canceled;
previous_bookings_not_canceled -> is_repeated_guest;
is_repeated_guest -> {different_room_assigned,is_canceled};
total_stay -> is_canceled;
guests -> is_canceled;
booking_changes -> different_room_assigned; booking_changes -> is_canceled;
hotel -> {different_room_assigned,is_canceled};
required_car_parking_spaces -> is_canceled;
total_of_special_requests -> {booking_changes,is_canceled};
country->{hotel, required_car_parking_spaces,total_of_special_requests};
market_segment->{hotel, required_car_parking_spaces,total_of_special_requests};
}"""
这里,**处理**是指分配与客户预订时预留的房间类型相同的房间。**结果**是指预订是否被取消。**共同原因**表示我们认为对**结果**和**处理**具有因果效应的变量。根据我们的因果假设,满足此标准的两个变量是**预订更改**和**未观测混杂因素**。因此,如果我们没有明确指定图(不推荐!),也可以将这些作为参数提供给下面的函数。
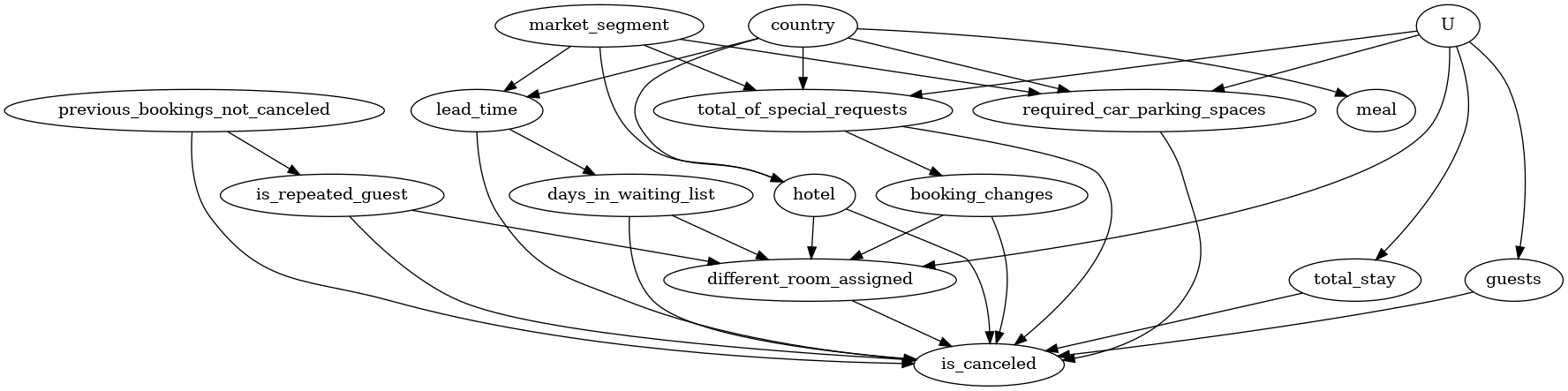
为了帮助识别因果效应,我们从图中移除了未观测的混杂因素节点。(要检查,您可以使用原始图并运行以下代码。identify_effect 方法将发现无法识别效应。)
[14]:
model= dowhy.CausalModel(
data = dataset,
graph=causal_graph.replace("\n", " "),
treatment="different_room_assigned",
outcome='is_canceled')
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
/__w/dowhy/dowhy/dowhy/causal_model.py:583: UserWarning: 1 variables are assumed unobserved because they are not in the dataset. Configure the logging level to `logging.WARNING` or higher for additional details.
warnings.warn(
步骤 2. 识别因果效应#
我们说如果改变**处理**会导致**结果**发生变化,同时保持其他所有条件不变,则处理导致结果。因此,在此步骤中,通过使用因果图的属性,我们识别了要估计的因果效应。
[15]:
#Identify the causal effect
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d ↪
──────────────────────────(E[is_canceled|days_in_waiting_list,booking_changes, ↪
d[different_room_assigned] ↪
↪ ↪
↪ lead_time,total_stay,guests,total_of_special_requests,required_car_parking_s ↪
↪ ↪
↪
↪ paces,hotel,is_repeated_guest])
↪
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,lead_time,total_stay,guests,total_of_special_requests,required_car_parking_spaces,hotel,is_repeated_guest,U) = P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,lead_time,total_stay,guests,total_of_special_requests,required_car_parking_spaces,hotel,is_repeated_guest)
### Estimand : 2
Estimand name: iv
No such variable(s) found!
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
步骤 3. 估计已识别的估计量#
[16]:
estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.propensity_score_weighting",target_units="ate")
# ATE = Average Treatment Effect
# ATT = Average Treatment Effect on Treated (i.e. those who were assigned a different room)
# ATC = Average Treatment Effect on Control (i.e. those who were not assigned a different room)
print(estimate)
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d ↪
──────────────────────────(E[is_canceled|days_in_waiting_list,booking_changes, ↪
d[different_room_assigned] ↪
↪ ↪
↪ lead_time,total_stay,guests,total_of_special_requests,required_car_parking_s ↪
↪ ↪
↪
↪ paces,hotel,is_repeated_guest])
↪
Estimand assumption 1, Unconfoundedness: If U→{different_room_assigned} and U→is_canceled then P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,lead_time,total_stay,guests,total_of_special_requests,required_car_parking_spaces,hotel,is_repeated_guest,U) = P(is_canceled|different_room_assigned,days_in_waiting_list,booking_changes,lead_time,total_stay,guests,total_of_special_requests,required_car_parking_spaces,hotel,is_repeated_guest)
## Realized estimand
b: is_canceled~different_room_assigned+days_in_waiting_list+booking_changes+lead_time+total_stay+guests+total_of_special_requests+required_car_parking_spaces+hotel+is_repeated_guest
Target units: ate
## Estimate
Mean value: -0.2622285649999514
/github/home/.cache/pypoetry/virtualenvs/dowhy-oN2hW5jr-py3.8/lib/python3.8/site-packages/sklearn/linear_model/_logistic.py:460: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.cn/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.cn/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
结果令人惊讶。这意味着分配不同的房间会**降低**取消的几率。这里还有更多值得深入探讨:这是正确的因果效应吗?是否可能只有在预订的房间不可用时才会分配不同的房间,因此分配不同的房间对客户产生积极影响(而不是不分配房间)?
可能还有其他机制在起作用。也许分配不同的房间只发生在入住时,而客户到达酒店后取消的可能性很低?在这种情况下,图缺少关于这些事件**何时**发生的关键变量。 different_room_assigned 是否主要发生在预订当天?了解该变量可以帮助改进图和我们的分析。
尽管早期的关联分析表明 is_canceled 和 different_room_assigned 之间存在正相关,但使用 DoWhy 估计因果效应呈现了不同的情况。这意味着减少酒店中 different_room_assigned 数量的决策/政策可能是适得其反的。
步骤 4. 反驳结果#
请注意,因果部分并非来自数据。它来自您的**假设**,这些假设导致了**识别**。数据仅用于统计**估计**。因此,验证我们的假设在第一步中是否正确变得至关重要!
当存在另一个共同原因时会发生什么?当处理本身是安慰剂时会发生什么?
方法 1#
**随机共同原因:-** *向数据添加随机抽取的协变量,并重新运行分析,以查看因果估计是否发生变化。如果我们的假设最初是正确的,那么因果估计不应该有太大变化。*
[17]:
refute1_results=model.refute_estimate(identified_estimand, estimate,
method_name="random_common_cause")
print(refute1_results)
Refute: Add a random common cause
Estimated effect:-0.2622285649999514
New effect:-0.26222856499995134
p value:1.0
方法 2#
**安慰剂处理反驳器:-** *随机将任何协变量指定为处理并重新运行分析。如果我们的假设是正确的,那么新发现的估计应该趋于 0。*
[18]:
refute2_results=model.refute_estimate(identified_estimand, estimate,
method_name="placebo_treatment_refuter")
print(refute2_results)
Refute: Use a Placebo Treatment
Estimated effect:-0.2622285649999514
New effect:0.05420218503316096
p value:0.0
方法 3#
**数据子集反驳器:-** *创建数据子集(类似于交叉验证),并检查因果估计是否在子集之间变化。如果我们的假设是正确的,则不应该有太大变化。*
[19]:
refute3_results=model.refute_estimate(identified_estimand, estimate,
method_name="data_subset_refuter")
print(refute3_results)
Refute: Use a subset of data
Estimated effect:-0.2622285649999514
New effect:-0.26239836091544644
p value:0.88
我们可以看到,我们的估计通过了所有三个反驳测试。这并不能证明其正确性,但增强了对估计值的信心。