反事实公平性#
本文使用 DoWhy 介绍并复现了 Kusner 等人 (2018) 提出的反事实公平性。
反事实公平性是一种个体层面的因果公平性度量,它捕捉了这样一个概念:如果估计器的决策在 (a) 现实世界中和 (b) 个体与不同人口群体相关的反事实世界中保持一致,那么该决策就被认为是公平的。
何时应用反事实公平性?#
用于评估预测是否具有个体因果公平性,即预测对于给定个体
i是否公平。
估计反事实公平性需要什么?#
包含受保护属性或代理变量的数据集。
结构因果模型 (SCM):可以使用 SCM 发现算法发现,或通过专家驱动的因果 DAG 创建。
符号#
A:个体的受保护属性集合,代表不得受到歧视的变量。
a:受保护属性在现实世界中取的实际值。
a’:受保护属性的反事实(/翻转)值。
X:任何特定个体的其他可观测属性。
U:未被观测到的相关潜在属性集合。
Y:要预测的结果,可能受到历史偏差的污染。
\(\hat{Y}\):预测器,一个随机变量,依赖于 A、X 和 U,由机器学习算法生成,作为 Y 的预测。
根据 Pearl 的定义,结构因果模型 M 被定义为一个四元组 (U, V, F, P(u)),可以使用有向无环图 (DAG) 表示,其中
U:由模型外部因素决定的外生(未观测到)变量集合。
V:内生(观测到)变量集合 {V1 … Vn},完全由模型中的变量(U 和 V)决定。注意:V 包括特征 X 和输出 Y。
F:结构方程集合 {f1 … fn},其中每个 fi 是 Vi 根据 U 和 V 当前(相关)值被赋予值 fi(v,u) 的过程。
P(u):U 的(先验)分布。
do(Zi = z):(Do) 干预 (Pearl 2000, Ch. 3),表示对 M 的操作,其中选定的干预变量 Z(V 的子集)的值被设置为常数 z,而不管这些值通常是如何由 DAG 生成的。这捕捉了系统外部的代理通过强制为 Zi 赋予值 z 来修改系统的想法(例如,在随机实验中)。在公平性文献中,Z 通常包含受保护属性,如种族、性别等。
M 是因果的,因为给定 P(U),在对子集 Z 进行 do 干预后,我们可以推导出 V 中其余未受干预变量的分布。
[1]:
import warnings
from collections import namedtuple
from typing import Any, Callable, Dict, List, Tuple, Union
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
import sklearn
from sklearn.neighbors import KernelDensity
from sklearn.mixture import GaussianMixture
from sklearn.linear_model import LogisticRegression, LinearRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.base import BaseEstimator
import warnings
import dowhy
import matplotlib.pyplot as plt
import dowhy.gcm as gcm
import networkx as nx
from sklearn import datasets, metrics
from typing import List, Any, Union
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.base import BaseEstimator
def analyse_counterfactual_fairness(
df: pd.DataFrame,
estimator: Union[BaseEstimator],
protected_attrs: List[str],
dag: List[Tuple],
X: List[str],
target: str,
disadvantage_group: dict,
intersectional: bool = False,
return_cache: bool = False,
) -> Union[float, Tuple[float, pd.DataFrame, pd.DataFrame]]:
"""
Calculates Counterfactual Fairness following Kusner et al. (2018)
Reference - https://arxiv.org/pdf/1703.06856.pdf
Args:
df (pd.DataFrame): Pandas DataFrame containing non-factorized/dummified versions of categorical
variables, the predicted ylabel, and other variables consumed by the predictive model.
estimator (Union[BaseEstimator]): Predictive model to be used for generating the output.
protected_attrs (List[str]): List of protected attributes in the dataset.
dag (List[Tuple]): List of tuples representing the Directed Acyclic Graph (DAG) structure.
X (List[str]): List of features to be used by the estimator.
target (str): Name of the target variable in df.
disadvantage_group (dict): Dictionary specifying the disadvantaged group for each protected attribute.
intersectional (bool, optional): If True, considers intersectional fairness. Defaults to False.
return_cache (bool, optional): If True, returns the counterfactual values with observed and
counterfactual protected attribute interventions for each row in df. Defaults to False.
Returns:
counterfactual_fairness (Union[float, Tuple[float, pd.DataFrame, pd.DataFrame]]):
- If return_cache is False, returns the calculated counterfactual fairness as a float.
- If return_cache is True, returns a tuple containing counterfactual fairness as a float,
DataFrame df_obs with observed counterfactual values, and DataFrame df_cf with perturbered counterfactual values.
"""
invt_local_causal_model = gcm.InvertibleStructuralCausalModel(nx.DiGraph(dag))
gcm.auto.assign_causal_mechanisms(invt_local_causal_model, df)
gcm.fit(invt_local_causal_model, df)
df_cf = pd.DataFrame()
df_obs = pd.DataFrame()
do_val_observed = {protected_attr: "observed" for protected_attr in protected_attrs}
do_val_counterfact = {protected_attr: "cf" for protected_attr in protected_attrs}
for idx, row in df.iterrows():
do_val_obs = {}
for protected_attr, intervention_type in do_val_observed.items():
intervention_val = float(
row[protected_attr]
if intervention_type == "observed"
else 1 - float(row[protected_attr])
)
do_val_obs[protected_attr] = _wrapper_lambda_fn(intervention_val)
do_val_cf = {}
for protected_attr, intervention_type in do_val_counterfact.items():
intervention_val = float(
float(row[protected_attr])
if intervention_type == "observed"
else 1 - float(row[protected_attr])
)
do_val_cf[protected_attr] = _wrapper_lambda_fn(intervention_val)
counterfactual_samples_obs = gcm.counterfactual_samples(
invt_local_causal_model, do_val_obs, observed_data=pd.DataFrame(row).T
)
counterfactual_samples_cf = gcm.counterfactual_samples(
invt_local_causal_model, do_val_cf, observed_data=pd.DataFrame(row).T
)
df_cf = pd.concat([df_cf, counterfactual_samples_cf])
df_obs = pd.concat([df_obs, counterfactual_samples_obs])
df_cf = df_cf.reset_index(drop=True)
df_obs = df_obs.reset_index(drop=True)
if hasattr(estimator, "predict_proba"):
# 1. Samples from the causal model based on the observed race
lr_observed = estimator()
lr_observed.fit(df_obs[X].astype(float), df[target])
df_obs[f"preds"] = lr_observed.predict_proba(df_obs[X].astype(float))[:, 1]
# 2. Samples from the causal model based on the counterfactual race
lr_cf = estimator()
lr_cf.fit(df_cf[X].astype(float), df[target])
df_cf[f"preds_cf"] = lr_cf.predict_proba(df_cf[X].astype(float))[:, 1]
else:
# 1. Samples from the causal model based on the observed race
lr_observed = estimator()
lr_observed.fit(df_obs[X].astype(float), df[target])
df_obs[f"preds"] = lr_observed.predict(df_obs[X].astype(float))
# 2. Samples from the causal model based on the counterfactual race
lr_cf = estimator()
lr_cf.fit(df_cf[X].astype(float), df[target])
df_cf[f"preds_cf"] = lr_cf.predict(df_cf[X].astype(float))
query = " and ".join(
f"{protected_attr} == {disadvantage_group[protected_attr]}"
for protected_attr in protected_attrs
)
mask = df.query(query).index.tolist()
counterfactual_fairness = (
df_obs.loc[mask]["preds"].mean() - df_cf.loc[mask]["preds_cf"].mean()
)
if not return_cache:
return counterfactual_fairness
else:
return counterfactual_fairness, df_obs, df_cf
def plot_counterfactual_fairness(
df_obs: pd.DataFrame,
df_cf: pd.DataFrame,
mask: pd.Series,
counterfactual_fairness: Union[int, float],
legend_observed: str,
legend_counterfactual: str,
target: str,
title: str,
) -> None:
"""
Plots counterfactual fairness comparing observed and counterfactual samples.
Args:
df_obs (pd.DataFrame): DataFrame containing observed samples.
df_cf (pd.DataFrame): DataFrame containing counterfactual samples.
mask (pd.Series): Boolean mask for selecting specific samples from the DataFrames.
counterfactual_fairness (Union[int, float]): The counterfactual fairness metric.
legend_observed (str): Legend label for the observed samples.
legend_counterfactual (str): Legend label for the counterfactual samples.
target (str): Name of the target variable to be plotted on the x-axis.
title (str): Title of the plot.
Returns:
None: The function displays the plot.
"""
fig, ax = plt.subplots(figsize=(8, 5), nrows=1, ncols=1)
ax.hist(
df_obs[f"preds"][mask], bins=50, alpha=0.7, label=legend_observed, color="blue"
)
ax.hist(
df_cf[f"preds_cf"][mask], bins=50, alpha=0.7, label=legend_counterfactual, color="orange"
)
ax.set_xlabel(target)
ax.legend()
ax.set_title(title)
fig.suptitle(f"Counterfactual Fairness {round(counterfactual_fairness, 3)}")
plt.tight_layout()
plt.show()
def _wrapper_lambda_fn(val):
return lambda x: val
1. 加载和清洗数据集#
Kusner 等人 (2018) 使用了法学院招生委员会进行的一项调查,涵盖美国 163 所法学院,收集了 21,790 名法学生的Ł数据。本案例研究中使用的数据集最初是 Linda Wightman 在 1998 年为一项名为“LSAC 全国长期律师执业考试通过率研究。LSAC 研究报告系列”的研究收集的。该调查包含以下详细信息:- 入学考试分数 (LSAT) - 法学院入学前平均绩点 (GPA) - 第一年平均成绩 (FYA)。
它还包括受保护属性,如:- 种族 - 性别
为了本示例的目的,我们将只关注白人和黑人子群体之间的结果差异,并将数据集限制在 5000 个个体的随机样本中
[2]:
df = pd.read_csv("datasets/law_data.csv")
df["Gender"] = df["sex"].map({2: 0, 1: 1}).astype(str)
df["Race"] = df["race"].map({"White": 0, "Black": 1}).astype(str)
df = (
df.query("race=='White' or race=='Black'")
.rename(columns={"UGPA": "GPA", "LSAT": "LSAT", "ZFYA": "avg_grade"})[
["Race", "Gender", "GPA", "LSAT", "avg_grade"]
]
.reset_index(drop=True)
)
df_sample = df.astype(float).sample(5000).reset_index(drop=True)
df_sample.head()
[2]:
| 种族 | 性别 | GPA | LSAT | avg_grade | |
|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 3.9 | 45.0 | 0.62 |
| 1 | 0.0 | 1.0 | 3.6 | 48.0 | 1.71 |
| 2 | 0.0 | 1.0 | 3.0 | 32.0 | 0.20 |
| 3 | 0.0 | 0.0 | 3.8 | 41.0 | 1.26 |
| 4 | 1.0 | 1.0 | 2.9 | 35.0 | -1.28 |
鉴于这些数据,学校可能希望预测申请者是否会有较高的 FYA。学校还希望确保这些预测不会因个人的种族和性别而产生偏见。然而,LSAT、GPA 和 FYA 分数可能由于社会因素而存在偏见。那么,我们如何确定这种预测模型对特定个体的偏见程度呢?使用反事实公平性。
2. 反事实公平性的正式定义#
反事实公平性要求,对于人群中的每个人,即使该个体在因果意义上具有不同的受保护属性,预测值也应保持不变。更正式地说,如果在任何上下文 X = x 和 A = a 下,\(\hat{Y}\) 都是反事实公平的
对于所有 y 和 A 可以取到的任何值 a’。这个概念与实际原因或 token 因果关系密切相关。本质上,为了公平,A 在任何特定实例中都不应该是 \(\hat{Y}\) 的直接原因,即在保持非因果依赖因素不变的情况下改变 A 不应改变 \(\hat{Y}\) 的分布。对于个体 i,由不同反事实世界生成的 Y 之间的差异可以理解为相似性的一种度量。
2.1 度量反事实公平性#
在 SCM M 中,任何可观测变量 (Vi) 的状态完全由背景变量 (U) 和结构方程 (F) 决定。因此,给定一组完全指定的方程,使用 SCM 我们可以构建反事实。也就是说
"we can compute what (the distribution of) any of the variables would have been had certain other variables been different, other things being equal. For instance, given the causal model we can ask “Would individual i have graduated (Y = 1) if they hadn’t had a job?”, even if they did not actually graduate in the dataset." - (Russell et. al. , 2017)
给定 SCM M 和证据 E(V 的子集),反事实分三步构建(即推断)
溯因:即使用 M,调整噪声变量以与观测证据 E 一致。更正式地说,给定 E 和 U 的先验分布 P(U),计算给定 M 的未观测变量集合 U 的值。对于非确定性模型(文献中大多数因果模型都是这种情况),计算后验分布 P(U|E=e)。
行动:对 Z 执行 do 干预(即 do(Zi = z)),从而得到干预后的 SCM 模型 M’。
预测:使用干预后的模型 M’ 和 P(U|E=e),计算 V 的反事实值(或 P(V |E=e))。
3. 使用 DoWhy 度量反事实公平性#
从算法角度,经验性地测试模型是否反事实公平
步骤 1 - 定义因果模型 基于因果 DAG
步骤 2 - 生成反事实样本:使用
gcm.counterfactual_samples,从模型生成两组样本一组使用受保护属性的观测值 (
df_obs)一组使用受保护属性的反事实值 (
df_cf)
步骤 3 - 使用样本数据拟合估计器:使用原始和反事实样本数据拟合模型,并绘制两个模型生成的预测目标分布。如果分布重叠,则估计器是反事实公平的;否则不是。
给定一个包含受保护/代理属性的数据集和一个因果 DAG,我们可以使用 analyse_counterfactual_fairness 函数来度量个体和总体层面的反事实公平性。在本示例中,我们基于 Kusner 等人 (2018) 提供的因果 DAG 创建因果 DAG。
[3]:
dag = [
("Race", "GPA"),
("Race", "LSAT"),
("Race", "avg_grade"),
("Gender", "GPA"),
("Gender", "LSAT"),
("Gender", "avg_grade"),
("GPA", "avg_grade"),
("LSAT", "avg_grade"),
]
analyse_counterfactual_fairness 方法还接受以下输入:- 目标变量的名称(这里是 target avg_grade)- 输入数据集(df)- 未拟合的 sklearn 估计器(estimator;这里是 LinearRegression)- 受保护属性列表(protected_attrs)- 输入特征名称列表(X)- 一个字典,指定每个受保护群体的弱势群体的唯一识别标签(disadvantage_group)。
[4]:
target = "avg_grade"
disadvantage_group = {"Race": 1}
protected_attrs = ["Race"]
features = ["GPA", "LSAT"]
3.1 单变量分析#
现在,我们可以调用 analyse_counterfactual_fairness 方法,沿种族维度进行反事实公平性分析
[5]:
config = {
"df": df_sample,
"dag": dag,
"estimator": LinearRegression,
"protected_attrs": protected_attrs,
"X": features,
"target": target,
"disadvantage_group": disadvantage_group,
"return_cache": True,
}
counterfactual_fairness, df_obs, df_cf = analyse_counterfactual_fairness(**config)
counterfactual_fairness
Fitting causal mechanism of node Gender: 100%|██████████| 5/5 [00:00<00:00, 55.16it/s]
[5]:
df_obs 包含现实世界中每个个体给定其受保护属性观测值时的预测值。
[6]:
df_obs.head()
[6]:
| 种族 | 性别 | GPA | LSAT | avg_grade | preds | |
|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 3.9 | 45.0 | 0.62 | 0.646472 |
| 1 | 0.0 | 1.0 | 3.6 | 48.0 | 1.71 | 0.685566 |
| 2 | 0.0 | 1.0 | 3.0 | 32.0 | 0.20 | -0.132365 |
| 3 | 0.0 | 0.0 | 3.8 | 41.0 | 1.26 | 0.455839 |
| 4 | 1.0 | 1.0 | 2.9 | 35.0 | -1.28 | -0.037868 |
df_cf 包含现实世界中每个个体给定其受保护属性反事实值时的预测值。在这里,由于我们只干预种族变量,我们看到每个个体的种族已从 0 更改为 1。
[7]:
df_cf.head()
[7]:
| 种族 | 性别 | GPA | LSAT | avg_grade | preds_cf | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.0 | 3.577589 | 37.124987 | -0.918331 | 0.278384 |
| 1 | 1.0 | 1.0 | 3.203434 | 40.124987 | 0.425989 | 0.263249 |
| 2 | 1.0 | 1.0 | 2.603434 | 24.124987 | -0.579415 | 0.048368 |
| 3 | 1.0 | 0.0 | 3.477589 | 33.124987 | -0.170558 | 0.230359 |
| 4 | 0.0 | 1.0 | 3.296566 | 42.875013 | -0.204968 | 0.299043 |
[8]:
plot_counterfactual_fairness(
df_obs=df_obs,
df_cf=df_cf,
mask=(df_sample["Race"] == 1).values,
counterfactual_fairness=counterfactual_fairness,
legend_observed="Observed Samples (Race=Black)",
legend_counterfactual="Counterfactual Samples (Race=White)",
target=target,
title="Black -> White",
)
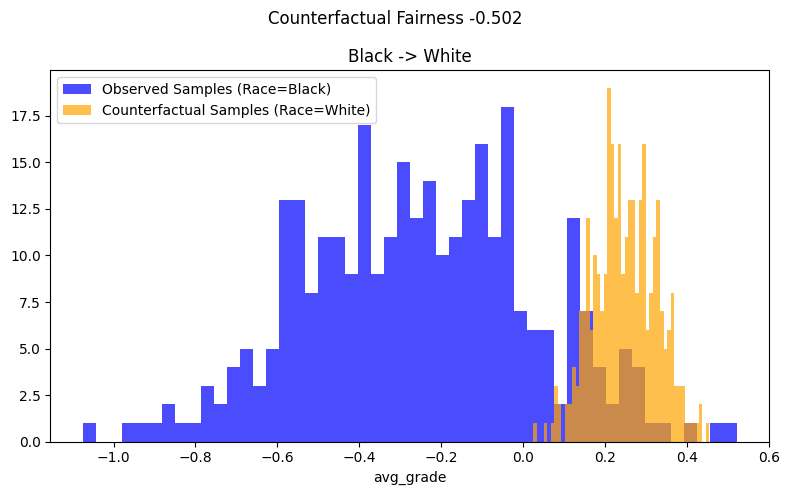
考察图 1 中的示例结果,我们看到观测分布和反事实分布不重叠。我们看到,将黑人子群体的种族改为白人子群体后,\(\hat{Y}\) 的分布向右移动,即平均使 avg_grade 增加了约 0.50。因此,可以得出结论,拟合的估计器不是反事实公平的。
3.2 交叉分析#
我们可以进一步进行交叉分析,共同考察多个受保护属性对反事实公平性的影响。在这里,我们使用两个可用的受保护属性 - ["Race","Gender"] - 进行交叉反事实公平性分析,以确定该估计器对黑人女性的反事实公平性程度。
[9]:
disadvantage_group = {"Race": 1, "Gender": 1}
config = {
"df": df_sample.astype(float).reset_index(drop=True),
"estimator": LinearRegression,
"protected_attrs": ["Race", "Gender"],
"dag": dag,
"X": features,
"target": "avg_grade",
"return_cache": True,
"disadvantage_group": disadvantage_group,
"intersectional": True,
}
counterfactual_fairness, df_obs, df_cf = analyse_counterfactual_fairness(**config)
counterfactual_fairness
Fitting causal mechanism of node Gender: 100%|██████████| 5/5 [00:00<00:00, 78.72it/s]
[9]:
[10]:
plot_counterfactual_fairness(
df_obs=df_obs,
df_cf=df_cf,
mask=((df_sample["Race"] == 1).values & (df_sample["Gender"] == 1).values),
counterfactual_fairness=counterfactual_fairness,
legend_observed="Observed Samples (Race=Black, Gender=Female)",
legend_counterfactual="Counterfactual Samples (Race=White, Gender=Male)",
target=target,
title="(Black, Female) -> (White, Male)",
)
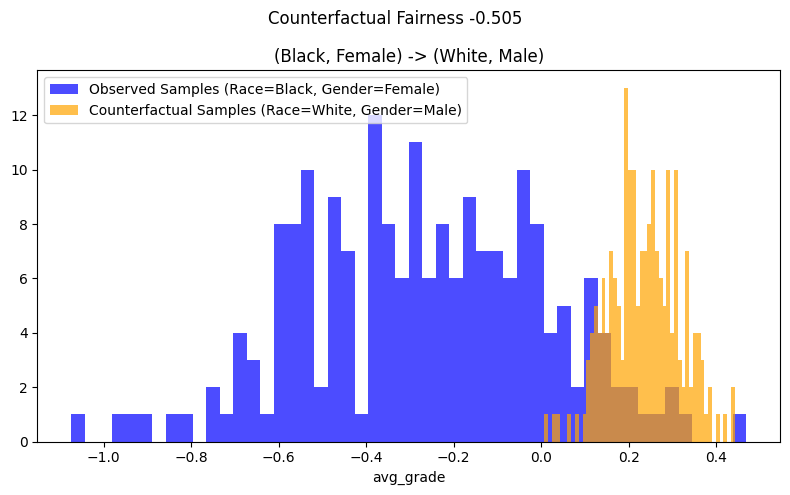
考察图 2 中的交叉分析结果,我们看到观测分布和反事实分布完全不重叠。将黑人女性的种族和性别改为白人男性后,黑人女性子群体的 \(\hat{Y}\) 分布向右移动,即平均使 avg_grade 增加了约 0.50。因此,可以得出结论,拟合的估计器在交叉层面上不是反事实公平的。
3.3 反事实 df_obs 和 df_cf 在公平性方面的其他一些用途#
Y 的反事实值(使用一组公平的因果模型构建)可以在存在历史偏见标签 Y 的情况下,用作训练模型的公平目标。
通过使用优化程序来训练一个估计器使其反事实公平,该程序对给定个体 i 应用与该个体 i 在不同反事实世界中 Y 的(平均)差异成比例的惩罚。例如,如果对于个体 i,Y 的结果在不同反事实世界中差异很大,那么样本 i 将使损失按比例增加更多。相反,如果对于个体 j,Y 的结果在不同反事实世界中相似,那么样本 j 将使损失按比例增加更少(更多细节请参见 Russell, Chris 等人,2017)。
4. 反事实公平性的局限性#
关于“正确”的因果模型可能存在分歧,原因包括
改变 DAG 的结构,例如增加一条边
改变潜在变量,例如改变生成节点的函数,使其具有不同的信号与噪声分解
阻止某些路径传播反事实值
文献建议在多个相互竞争的因果模型下实现反事实公平性作为上述问题的解决方案。Russell 等人 (2017) 提出了一种这样的解决方案,称为“多世界公平性算法”。
参考文献#
Kusner, Matt 等人。Counterfactual Fairness. 2018, https://arxiv.org/pdf/1703.06856.pdf
Russell, Chris 等人。When Worlds Collide: Integrating Different Counterfactual Assumptions In Fairness. 2017, https://proceedings.neurips.cc/paper/2017/file/1271a7029c9df08643b631b02cf9e116-Paper.pdf
附录:通过无意识实现公平 (FTU) 会创建一个反事实不公平的估计器#
为了证明“有意识”线性回归总是反事实公平的,但 FTU 使其反事实不公平,我们构建了一个“有意识”线性回归,并将其与图 1 构建的“无意识”线性回归进行比较。
[11]:
config = {
"df": df_sample,
"estimator": LinearRegression,
"protected_attrs": ["Race"],
"dag": dag,
"X": ["GPA", "LSAT", "Race", "Gender"],
"target": "avg_grade",
"return_cache": True,
"disadvantage_group": disadvantage_group,
}
counterfactual_fairness_aware, df_obs_aware, df_cf_aware = (
analyse_counterfactual_fairness(**config)
)
counterfactual_fairness_aware
Fitting causal mechanism of node Gender: 100%|██████████| 5/5 [00:00<00:00, 63.95it/s]
[11]:
[12]:
plot_counterfactual_fairness(
df_obs=df_obs_aware,
df_cf=df_cf_aware,
mask=(df_sample["Race"] == 1).values,
counterfactual_fairness=counterfactual_fairness_aware,
legend_observed="Observed Samples (Race=Black)",
legend_counterfactual="Counterfactual Samples (Race=White)",
target=target,
title="Black -> White",
)
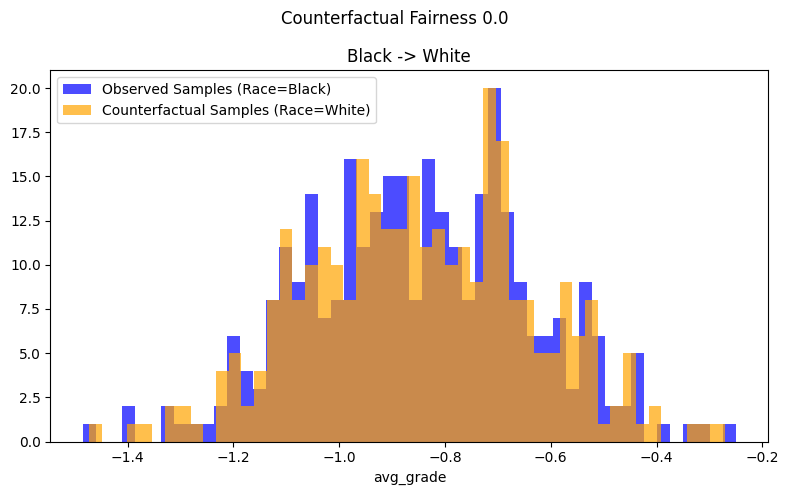
比较图 1 和图 3,观测反事实样本 df_obs 和扰动反事实样本 df_cf 的对比图显示
对于图 3 中的“有意识”线性回归,两个分布重叠。因此,估计器是反事实公平的。
对于图 1 中的“无意识”线性回归,两个分布相当不同且不重叠,表明该估计器是反事实不公平的,即仅对 GPA 和 LSAT 进行 avg_grade 回归会使估计器反事实不公平。
值得注意的是,可以正式证明,一般来说,“仅将 Y 回归到 X 上符合 FTU 标准,但不是反事实公平的,因此省略 A (FTU) 可能会在原本公平的世界中引入不公平性”。(Kusner et al. 2018)