非参数因果估计量的敏感性分析#
敏感性分析帮助我们研究,当不观测混杂的假设被违反时,估计的效应有多稳健。也就是说,由于遗漏了(未观测的)混杂因素,我们的估计值有多少偏差?这被称为遗漏变量偏差 (OVB),它衡量了包含一个遗漏的共同原因(混杂因素)会如何改变估计的效应。
本 Notebook 展示了如何对一般的非参数因果估计量进行 OVB 估计。为了获得直观理解,我们建议先阅读介绍性 Notebook,其中描述了如何对线性估计量进行 OVB 估计:线性估计量的敏感性分析。回顾一下,在该 Notebook 中,我们看到了 OVB 如何依赖于线性偏 R^2 值,并利用这一见解根据混杂因素与结果和处理的相对强度计算调整后的估计值。现在,我们使用非参数偏 R^2 和 Reisz 表示泛化该技术。
本 Notebook 基于 Chernozhukov 等人,Long Story Short: Omitted Variable Bias in Causal Machine Learning. https://arxiv.org/abs/2112.13398。
I. 部分线性模型的敏感性分析#
我们首先分析当已知真实数据生成过程 (DGP) 是部分线性时,因果估计的敏感性。也就是说,结果可以加性分解为处理的线性函数和混杂因素的非线性函数。我们将处理记为 \(T\),结果记为 \(Y\),观测混杂因素记为 \(W\),未观测混杂因素记为 \(U\)。
然而,由于混杂因素 \(U\) 未被观测到,我们无法估计上述方程。因此,在实践中,因果估计量使用以下“简短”方程,
敏感性分析的目标是回答 \(\theta_s\) 会与真实 \(\theta\) 相差多远。Chernozhukov 等人表明,给定一个称为 Reisz 函数 \(\alpha\) 的特殊函数,遗漏变量偏差 \(|\theta - \theta_s|\) 的界限是 \(\sqrt{E[g-g_s]^2E[\alpha-\alpha_s]^2}\)。对于部分线性模型,\(\alpha\) 和“简短” \(\alpha_s\) 定义为,
该界限可以用未观测混杂因素 \(U\) 与处理和结果之间的偏 R^2 表示,以观测混杂因素 \(W\) 为条件。回想一下,\(U\) 关于某个目标 \(Z\) 的 R^2 定义为预测 \(E[Z|U]\) 的方差与 \(Z\) 的方差之比,\(R^2_{Z\sim U}=\frac{\operatorname{Var}(E[Z|U])}{\operatorname{Var}(Y)}\)。我们可以将偏 R^2 定义为一个扩展,衡量以某些变量 \(W\) 为条件时解释力的额外增益。
界限由下式给出,
其中,
\(S^2\) 可以从数据中估计。其他两个参数需要手动指定:它们表示未观测混杂因素 \(U\) 对处理和结果的影响强度。下面我们将展示如何通过指定 \(\eta^2_{Y \sim U | T, W}\) 和 \(\eta^2_{T\sim U | W}\) 的合理值范围来创建敏感性等高线图。我们还将展示如何通过基准测试将这些值设置为任何观测协变量子集导致的最大偏 R^2 的一个分数。
创建具有未观测混杂因素的数据集#
[1]:
%load_ext autoreload
%autoreload 2
[2]:
# Required libraries
import re
import numpy as np
import dowhy
from dowhy import CausalModel
import dowhy.datasets
from dowhy.utils.regression import create_polynomial_function
我们创建一个数据集,其中处理和结果之间存在线性关系,遵循部分线性数据生成过程。\(\beta\) 是真实的因果效应。
[3]:
np.random.seed(101)
data = dowhy.datasets.partially_linear_dataset(beta = 10,
num_common_causes = 7,
num_unobserved_common_causes=1,
strength_unobserved_confounding=10,
num_samples = 1000,
num_treatments = 1,
stddev_treatment_noise = 10,
stddev_outcome_noise = 5
)
display(data)
{'df': W0 W1 W2 W3 W4 W5 W6 \
0 0.345542 0.696984 -0.708658 -1.997165 -0.709139 0.165913 -0.554212
1 -0.075270 1.652779 -0.259591 0.282963 -0.764418 0.032002 -0.360908
2 -0.240272 -0.174564 -0.934469 -0.451650 1.959730 1.201015 0.471282
3 0.119874 -0.256127 0.318636 -0.223625 0.233940 1.549934 -0.763879
4 0.179436 1.410457 -0.635170 -1.263762 1.289872 -0.528325 0.122878
.. ... ... ... ... ... ... ...
995 1.131240 0.084704 -1.837648 -0.250193 -0.774702 -0.466984 -0.979246
996 -0.581574 0.167608 -1.914603 -0.653232 2.027677 0.513934 -1.188357
997 0.009781 2.095094 -1.417172 -0.118229 1.953746 0.357782 -0.129897
998 -0.310415 0.410795 -0.205454 -0.818042 0.747265 1.235053 0.627017
999 -0.015367 -0.026768 -0.390476 -0.064762 -0.095389 0.911950 0.329420
v0 y
0 True 8.391102
1 True 21.853491
2 False 1.247109
3 True 13.881250
4 True 13.929866
.. ... ...
995 True 14.289693
996 False 6.831359
997 True 10.695485
998 False -8.849379
999 True 13.994482
[1000 rows x 9 columns],
'treatment_name': ['v0'],
'outcome_name': 'y',
'common_causes_names': ['W0', 'W1', 'W2', 'W3', 'W4', 'W5', 'W6'],
'dot_graph': 'digraph {v0->y;W0-> v0; W1-> v0; W2-> v0; W3-> v0; W4-> v0; W5-> v0; W6-> v0;W0-> y; W1-> y; W2-> y; W3-> y; W4-> y; W5-> y; W6-> y;}',
'gml_graph': 'graph[directed 1node[ id "y" label "y"]node[ id "W0" label "W0"] node[ id "W1" label "W1"] node[ id "W2" label "W2"] node[ id "W3" label "W3"] node[ id "W4" label "W4"] node[ id "W5" label "W5"] node[ id "W6" label "W6"]node[ id "v0" label "v0"]edge[source "v0" target "y"]edge[ source "W0" target "v0"] edge[ source "W1" target "v0"] edge[ source "W2" target "v0"] edge[ source "W3" target "v0"] edge[ source "W4" target "v0"] edge[ source "W5" target "v0"] edge[ source "W6" target "v0"]edge[ source "W0" target "y"] edge[ source "W1" target "y"] edge[ source "W2" target "y"] edge[ source "W3" target "y"] edge[ source "W4" target "y"] edge[ source "W5" target "y"] edge[ source "W6" target "y"]]',
'ate': 10.085246711266985}
此数据生成过程的真实 ATE 为,
[4]:
data["ate"]
[4]:
为了模拟未观测混杂,我们从数据集中移除一个共同原因。
[5]:
# Observed data
dropped_cols=["W0"]
user_data = data["df"].drop(dropped_cols, axis = 1)
# assumed graph
user_graph = data["gml_graph"]
for col in dropped_cols:
user_graph = user_graph.replace('node[ id "{0}" label "{0}"]'.format(col), '')
user_graph = re.sub('edge\[ source "{}" target "[vy][0]*"\]'.format(col), "", user_graph)
user_data
[5]:
| W1 | W2 | W3 | W4 | W5 | W6 | v0 | y | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.696984 | -0.708658 | -1.997165 | -0.709139 | 0.165913 | -0.554212 | True | 8.391102 |
| 1 | 1.652779 | -0.259591 | 0.282963 | -0.764418 | 0.032002 | -0.360908 | True | 21.853491 |
| 2 | -0.174564 | -0.934469 | -0.451650 | 1.959730 | 1.201015 | 0.471282 | False | 1.247109 |
| 3 | -0.256127 | 0.318636 | -0.223625 | 0.233940 | 1.549934 | -0.763879 | True | 13.881250 |
| 4 | 1.410457 | -0.635170 | -1.263762 | 1.289872 | -0.528325 | 0.122878 | True | 13.929866 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 0.084704 | -1.837648 | -0.250193 | -0.774702 | -0.466984 | -0.979246 | True | 14.289693 |
| 996 | 0.167608 | -1.914603 | -0.653232 | 2.027677 | 0.513934 | -1.188357 | False | 6.831359 |
| 997 | 2.095094 | -1.417172 | -0.118229 | 1.953746 | 0.357782 | -0.129897 | True | 10.695485 |
| 998 | 0.410795 | -0.205454 | -0.818042 | 0.747265 | 1.235053 | 0.627017 | False | -8.849379 |
| 999 | -0.026768 | -0.390476 | -0.064762 | -0.095389 | 0.911950 | 0.329420 | True | 13.994482 |
1000 行 × 8 列
使用模型、识别、估计步骤获取因果估计#
使用“观测”数据和因果图创建因果模型。
[6]:
model = CausalModel(
data=user_data,
treatment=data["treatment_name"],
outcome=data["outcome_name"],
graph=user_graph,
test_significance=None,
)
model.view_model()
from IPython.display import Image, display
display(Image(filename="causal_model.png"))
[7]:
# Identify effect
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)
print(identified_estimand)
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W1,W6,W3,W4,W5,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W1,W6,W3,W4,W5,W2,U) = P(y|v0,W1,W6,W3,W4,W5,W2)
### Estimand : 2
Estimand name: iv
No such variable(s) found!
### Estimand : 3
Estimand name: frontdoor
No such variable(s) found!
[8]:
# Estimate effect
import econml
from sklearn.ensemble import GradientBoostingRegressor
linear_dml_estimate = model.estimate_effect(identified_estimand,
method_name="backdoor.econml.dml.dml.LinearDML",
method_params={
'init_params': {'model_y':GradientBoostingRegressor(),
'model_t': GradientBoostingRegressor(),
'linear_first_stages': False
},
'fit_params': {'cache_values': True,}
})
print(linear_dml_estimate)
A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W1,W6,W3,W4,W5,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W1,W6,W3,W4,W5,W2,U) = P(y|v0,W1,W6,W3,W4,W5,W2)
## Realized estimand
b: y~v0+W1+W6+W3+W4+W5+W2 |
Target units: ate
## Estimate
Mean value: 11.709254833402818
Effect estimates: [[11.70925483]]
使用反驳步骤进行敏感性分析#
估计后,我们需要检查我们的估计值对于可能存在未观测混杂因素的稳健性。我们对 LinearDML 估计量进行敏感性分析,假设其数据生成过程的假设成立:\(Y\) 的真实函数是部分线性的。为了提高计算效率,我们在 fit_params 中设置 cache_values = True 以缓存第一阶段估计的结果。
使用的参数
method_name: 反驳方法名称
simulation_method: “non-parametric-partial-R2” 用于非参数敏感性分析。注意,如果使用 LinearDML 估计量进行估计,会自动选择部分线性敏感性分析。
partial_r2_confounder_treatment: \(\eta^2_{T\sim U | W}\),未观测混杂因素与处理在所有观测混杂因素条件下的偏 R2。
partial_r2_confounder_outcome: \(\eta^2_{Y \sim U | T, W}\),未观测混杂因素与结果在处理和所有观测混杂因素条件下的偏 R2。
[9]:
refute = model.refute_estimate(identified_estimand, linear_dml_estimate ,
method_name = "add_unobserved_common_cause",
simulation_method = "non-parametric-partial-R2",
partial_r2_confounder_treatment = np.arange(0, 0.8, 0.1),
partial_r2_confounder_outcome = np.arange(0, 0.8, 0.1)
)
print(refute)
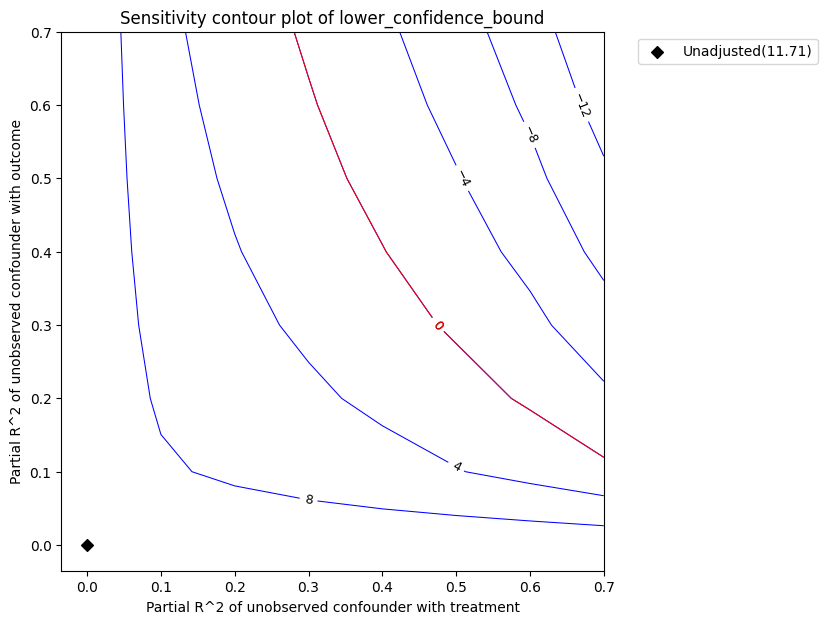
Sensitivity Analysis to Unobserved Confounding using partial R^2 parameterization
Original Effect Estimate : 11.709254833402818
Robustness Value : 0.45
Robustness Value (alpha=0.05) : 0.41000000000000003
Interpretation of results :
Any confounder explaining less than 45.0% percent of the residual variance of both the treatment and the outcome would not be strong enough to explain away the observed effect i.e bring down the estimate to 0
For a significance level of 5.0%, any confounder explaining more than 41.0% percent of the residual variance of both the treatment and the outcome would be strong enough to make the estimated effect not 'statistically significant'
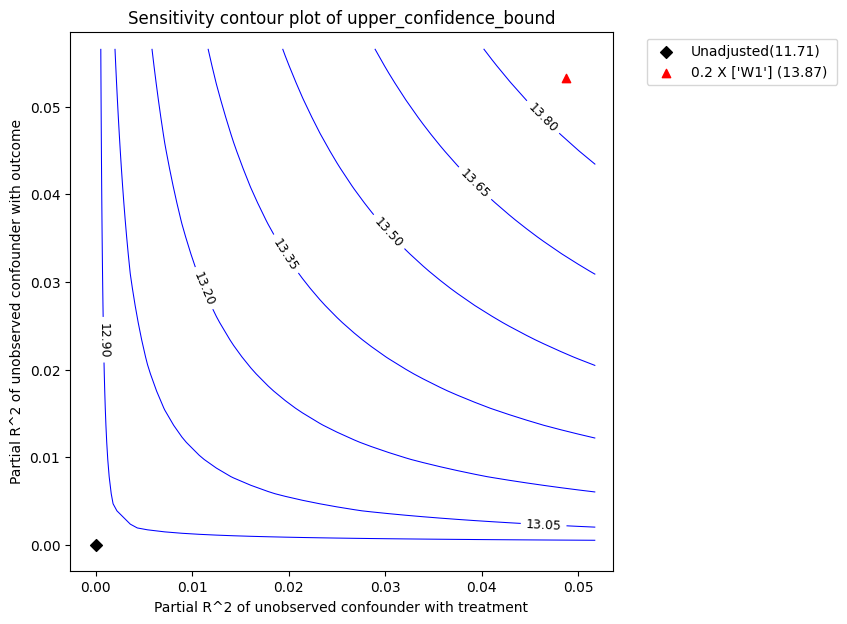
图解。在上图中,x 轴显示了未观测混杂因素与处理的假设偏 R2 值。y 轴显示了未观测混杂因素与结果的假设偏 R2 值。在 <x=0,y=0> 处,黑菱形显示了未考虑未观测混杂因素的原始估计值 (theta_s)。
等高线水平表示效应的调整后较低置信界估计,如果将未观测混杂因素包含在估计模型中,就会得到这个值。红色等高线是调整后效应变为零的关键阈值。因此,具有这种强度或更强的混杂因素足以反转估计效应的符号并使估计的结论失效。可以通过输出稳健性值来量化这个概念。
[10]:
refute.RV
[10]:
稳健性值衡量了 \(\eta^2_{T\sim U | W}\) 和 \(\eta^2_{Y \sim U | T, W}\) 的最小相等强度,使得平均处理效应的界限将包含零。它的取值范围在 0 到 1 之间。稳健性值为 0.45 意味着 \(\eta^2_{T\sim U | W}\) 和 \(\eta^2_{Y \sim U | T, W}\) 值小于 0.4 的混杂因素不足以将估计值降至零。一般来说,低稳健性值意味着即使存在弱混杂因素,结果也可能改变;而接近 1 的稳健性值意味着处理效应即使面对可能解释处理和结果所有残差变异的强混杂因素也能保持稳健。
基准测试。然而,通常很难提供一个合理的偏 R2 值范围。相反,我们可以将未观测混杂因素的偏 R2 推断为任何观测混杂因素子集偏 R2 的倍数。因此,我们现在只需将未观测混杂的影响指定为观测混杂的倍数/分数。这个过程称为基准测试。
基准测试的相关参数有:- benchmark_common_causes:用于限制未观测混杂因素强度的观测混杂因素名称 - effect_fraction_on_treatment:未观测混杂因素与处理之间关联强度相对于基准混杂因素的比例 - effect_fraction_on_outcome:未观测混杂因素与结果之间关联强度相对于基准混杂因素的比例
[11]:
refute_bm = model.refute_estimate(identified_estimand, linear_dml_estimate ,
method_name = "add_unobserved_common_cause",
simulation_method = "non-parametric-partial-R2",
benchmark_common_causes = ["W1"],
effect_fraction_on_treatment = 0.2,
effect_fraction_on_outcome = 0.2
)
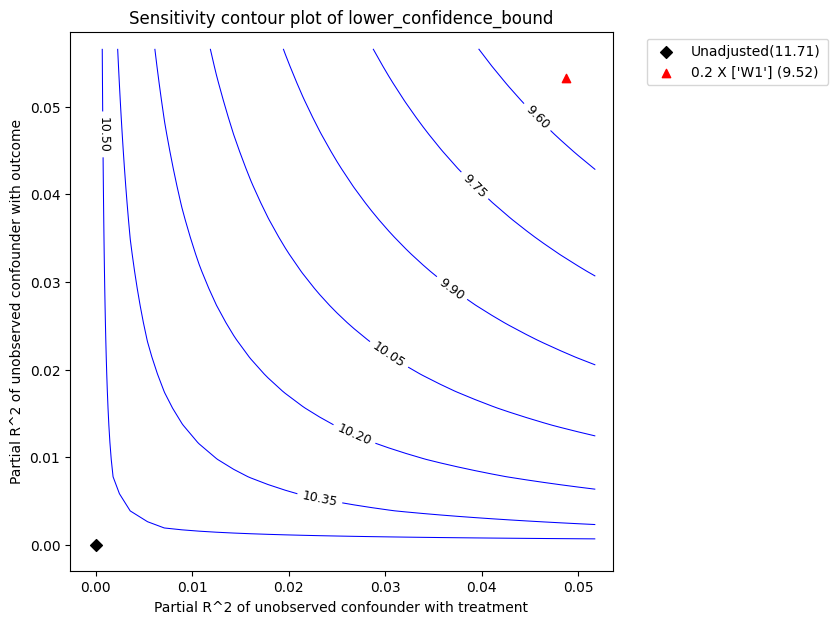
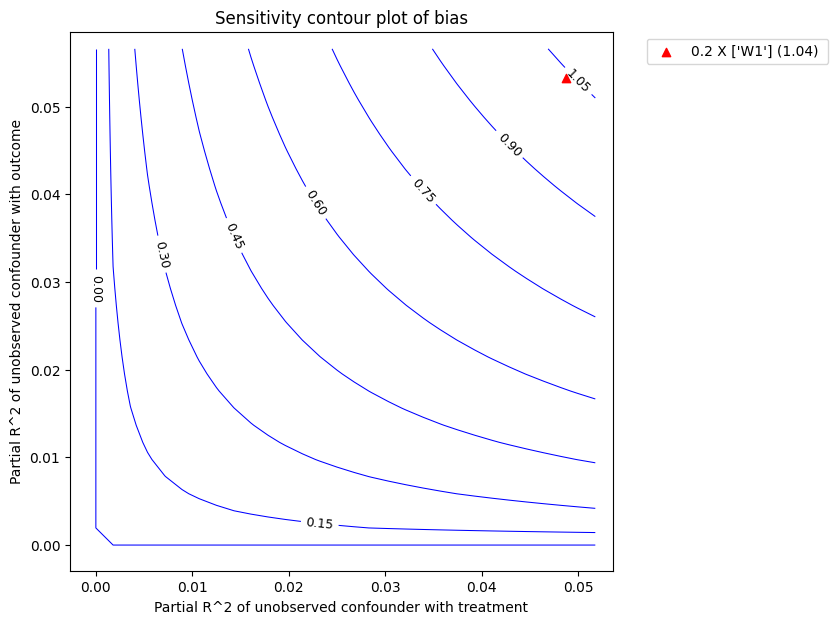
红色三角形显示了选定的基准观测协变量与处理和结果的估计偏 R^2。在上面的调用中,我们选择 W1 作为基准协变量。假设未观测混杂因素对处理和结果的影响不会强于观测基准协变量(W1),上图显示,在考虑未观测混杂因素后,平均估计效应会减小,但仍远大于零。
图类型。默认的 plot_type 是在显著性水平下显示 lower_confidence_bound。 plot_type 的其他可能值有:* upper_confidence_bound:通常用于预期未观测混杂因素会降低估计值的情况。* lower_ate_bound:未考虑显著性水平的无混杂平均处理效应的下(点)估计值。* upper_ate_bound:未考虑显著性水平的无混杂平均处理效应的上(点)估计值。* bias:获得的估计值与真实估计值之间的偏差。
[12]:
refute_bm.plot(plot_type = "upper_confidence_bound")
refute_bm.plot(plot_type = "bias")
我们也可以将基准测试结果作为数据框访问。
[13]:
refute_bm.results
[13]:
| r2tu_w | r2yu_tw | 简短估计 | 偏差 | lower_ate_bound | upper_ate_bound | lower_confidence_bound | upper_confidence_bound | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.0487 | 0.053207 | 11.709255 | 1.038683 | 10.670572 | 12.747937 | 9.522549 | 13.868991 |
II. 一般非参数模型的敏感性分析#
现在,我们在不对真实数据生成过程做任何假设的情况下进行敏感性分析。敏感性仍然取决于未观测混杂因素与结果的偏 R2 (\(\eta^2_{Y \sim U | T, W}\)),以及混杂因素与处理关系的一个类似参数。然而,界限的计算更为复杂,需要估计一个称为 Reisz 函数的特殊函数。有关详细信息,请参阅 Chernozhukov 等人。
[14]:
# Estimate effect using a non-parametric estimator
from sklearn.ensemble import GradientBoostingRegressor
estimate_npar = model.estimate_effect(identified_estimand,
method_name="backdoor.econml.dml.KernelDML",
method_params={
'init_params': {'model_y':GradientBoostingRegressor(),
'model_t': GradientBoostingRegressor(), },
'fit_params': {},
})
print(estimate_npar)
A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
*** Causal Estimate ***
## Identified estimand
Estimand type: EstimandType.NONPARAMETRIC_ATE
### Estimand : 1
Estimand name: backdoor
Estimand expression:
d
─────(E[y|W1,W6,W3,W4,W5,W2])
d[v₀]
Estimand assumption 1, Unconfoundedness: If U→{v0} and U→y then P(y|v0,W1,W6,W3,W4,W5,W2,U) = P(y|v0,W1,W6,W3,W4,W5,W2)
## Realized estimand
b: y~v0+W1+W6+W3+W4+W5+W2 |
Target units: ate
## Estimate
Mean value: 11.831292187241948
Effect estimates: [[11.83129219]]
为了进行敏感性分析,我们现在使用相同的 non-parametric--partial-R2 方法,但偏 R2 的估计将基于 Reisz 表示。我们使用 plugin_reisz=True 来指定我们将使用插件式 Reisz 函数估计量(这对于二元处理更快且可用)。否则,我们可以将其设置为 False,以使用损失函数估计 Reisz 函数。
[15]:
refute_npar = model.refute_estimate(identified_estimand, estimate_npar,
method_name = "add_unobserved_common_cause",
simulation_method = "non-parametric-partial-R2",
benchmark_common_causes = ["W1"],
effect_fraction_on_treatment = 0.2,
effect_fraction_on_outcome = 0.2,
plugin_reisz=True
)
print(refute_npar)
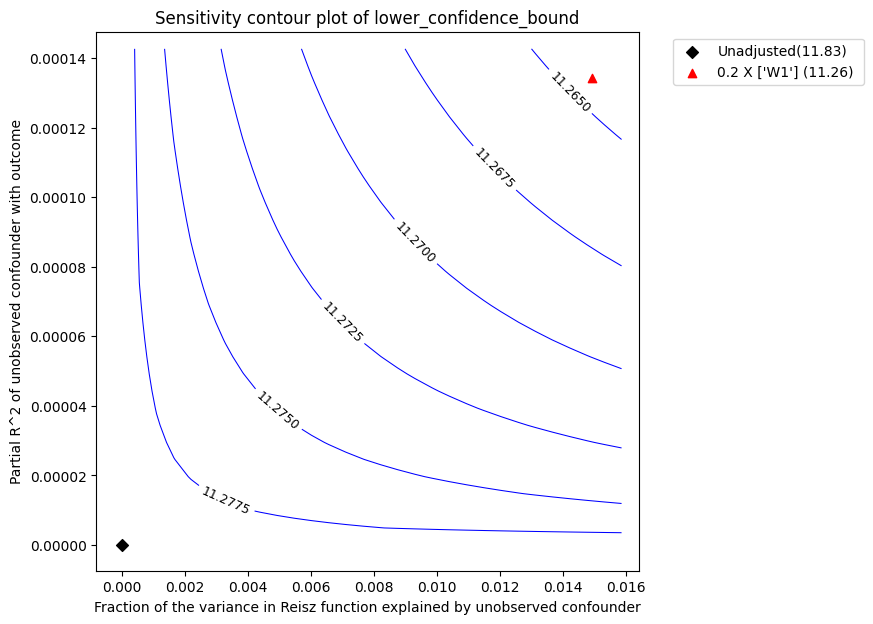
Sensitivity Analysis to Unobserved Confounding using partial R^2 parameterization
Original Effect Estimate : 11.831292187241948
Robustness Value : 0.66
Robustness Value (alpha=0.05) : 0.64
Interpretation of results :
Any confounder explaining less than 66.0% percent of the residual variance of both the treatment and the outcome would not be strong enough to explain away the observed effect i.e bring down the estimate to 0
For a significance level of 5.0%, any confounder explaining more than 64.0% percent of the residual variance of both the treatment and the outcome would be strong enough to make the estimated effect not 'statistically significant'
该图的解释与之前相同。我们获得的稳健性值为 0.66,而 LinearDML 估计量的稳健性值为 0.45。
请注意,即使 LinearDML 和 KernelDML 的点估计值相似,稳健性值也会发生变化。这是因为我们对真实数据生成过程做了不同的假设。