在现实世界示例中估计内在因果影响#
本笔记本演示了内在因果影响(ICC)方法的使用,该方法是一种估计系统中因果影响的方式。许多应用中的一个常见问题是:“节点 X 对节点 Y 的因果影响是什么?”在这里,“因果影响”可以用多种方式定义。一种方法是衡量干预影响,它询问“如果我干预节点 X,节点 Y 会改变多少?”或者,从更侧重特征相关性的角度来看,“X 在描述 Y 方面有多相关?”
在下文中,我们将重点讨论一种特定类型的因果影响,该影响基于将生成过程分解为每个节点处的机制(由相应的因果机制形式化)。然后,ICC 为每个节点量化了可以追溯到相应机制的目标不确定性量。因此,从其父节点确定性计算的节点贡献为零。这个概念起初可能看起来很复杂,但它是基于一个简单的想法
考虑一个节点链:X -> Y -> Z。Y 比 X 提供更多关于 Z 的信息,因为 Y 直接决定 Z,并且还包含来自 X 的所有信息。显而易见的是,当干预 X 或 Y 时,Y 对 Z 的影响更大。但是,如果 Y 只是 X 的缩放副本,即 \(Y = a \cdot X\) 呢?在这种情况下,Y 对 Z 仍然有最大的干预影响,但它没有在 X 之上添加任何新信息。另一方面,ICC 方法会将 Y 的影响归零,因为它只传递从 X 继承的信息。
ICC 背后的思想不是估计观测到的上游节点对目标节点的贡献,而是归因于它们噪声项的影响。由于我们将每个节点建模为形式为 \(X_i = f_i(PA_i, N_i)\) 的函数因果模型,我们的目标是估计 \(N_i\) 项对目标的贡献。在前面的例子中,我们有零噪声的确定性关系,即内在影响为 0。这种类型的归因只有在我们使用函数因果模型显式建模因果关系时才可能实现,就像我们在 GCM 模块中所做的那样。
在下文中,我们将研究两个应用 ICC 的现实世界示例。
汽车 MPG 消耗的内在影响#
在第一个示例中,我们使用著名的MPG 数据集,该数据集包含用于预测汽车发动机每加仑英里数 (mpg) 的不同特征。假设我们的任务是改进设计过程,其中我们需要很好地理解变量对 mpg 消耗的影响。这些特征之间的关系可以建模为图因果模型。为此,我们遵循Wang 等人的工作中定义的因果图,并移除所有对 MPG 没有影响的节点。这给我们留下了以下图
[1]:
import pandas as pd
import networkx as nx
import numpy as np
from dowhy import gcm
from dowhy.utils.plotting import plot, bar_plot
gcm.util.general.set_random_seed(0)
# Load a modified version of the Auto MPG data: Quinlan,R.. (1993). Auto MPG. UCI Machine Learning Repository. https://doi.org/10.24432/C5859H.
auto_mpg_data = pd.read_csv("datasets/auto_mpg.csv", index_col=0)
mpg_graph = nx.DiGraph([('cylinders', 'displacement'),
('cylinders', 'displacement'),
('displacement', 'weight'),
('displacement', 'horsepower'),
('weight', 'mpg'),
('horsepower', 'mpg')])
plot(mpg_graph)
看到这张图,我们可以预期节点之间存在一些强烈的混淆因素,但尽管如此,我们将看到 ICC 方法仍然提供了非平凡的见解。
让我们定义相应的结构因果模型并将其拟合到数据中
[2]:
scm_mpg = gcm.StructuralCausalModel(mpg_graph)
gcm.auto.assign_causal_mechanisms(scm_mpg, auto_mpg_data)
gcm.fit(scm_mpg, auto_mpg_data)
Fitting causal mechanism of node mpg: 100%|██████████| 5/5 [00:00<00:00, 30.05it/s]
或者,我们可以使用评估方法来了解因果机制的性能
[3]:
print(gcm.evaluate_causal_model(scm_mpg, auto_mpg_data, evaluate_invertibility_assumptions=False, evaluate_causal_structure=False))
Evaluating causal mechanisms...: 100%|██████████| 5/5 [00:00<00:00, 5281.17it/s]
Evaluated the performance of the causal mechanisms and the overall average KL divergence between generated and observed distribution. The results are as follows:
==== Evaluation of Causal Mechanisms ====
The used evaluation metrics are:
- KL divergence (only for root-nodes): Evaluates the divergence between the generated and the observed distribution.
- Mean Squared Error (MSE): Evaluates the average squared differences between the observed values and the conditional expectation of the causal mechanisms.
- Normalized MSE (NMSE): The MSE normalized by the standard deviation for better comparison.
- R2 coefficient: Indicates how much variance is explained by the conditional expectations of the mechanisms. Note, however, that this can be misleading for nonlinear relationships.
- F1 score (only for categorical non-root nodes): The harmonic mean of the precision and recall indicating the goodness of the underlying classifier model.
- (normalized) Continuous Ranked Probability Score (CRPS): The CRPS generalizes the Mean Absolute Percentage Error to probabilistic predictions. This gives insights into the accuracy and calibration of the causal mechanisms.
NOTE: Every metric focuses on different aspects and they might not consistently indicate a good or bad performance.
We will mostly utilize the CRPS for comparing and interpreting the performance of the mechanisms, since this captures the most important properties for the causal model.
--- Node cylinders
- The KL divergence between generated and observed distribution is 0.0.
The estimated KL divergence indicates an overall very good representation of the data distribution.
--- Node displacement
- The MSE is 1038.9343497781185.
- The NMSE is 0.3099451012063349.
- The R2 coefficient is 0.902742668556819.
- The normalized CRPS is 0.1751548596208045.
The estimated CRPS indicates a very good model performance.
--- Node weight
- The MSE is 77457.72022070756.
- The NMSE is 0.32835606557278874.
- The R2 coefficient is 0.8906984502441844.
- The normalized CRPS is 0.18152066920237506.
The estimated CRPS indicates a very good model performance.
--- Node horsepower
- The MSE is 219.4080817916261.
- The NMSE is 0.3928982373568955.
- The R2 coefficient is 0.8442300802658049.
- The normalized CRPS is 0.20931589069850634.
The estimated CRPS indicates a good model performance.
--- Node mpg
- The MSE is 15.77477783171984.
- The NMSE is 0.525697653901878.
- The R2 coefficient is 0.7214631910370037.
- The normalized CRPS is 0.28731346321872775.
The estimated CRPS indicates a good model performance.
==== Evaluation of Generated Distribution ====
The overall average KL divergence between the generated and observed distribution is 1.004787953076203
The estimated KL divergence indicates some mismatches between the distributions.
==== NOTE ====
Always double check the made model assumptions with respect to the graph structure and choice of causal mechanisms.
All these evaluations give some insight into the goodness of the causal model, but should not be overinterpreted, since some causal relationships can be intrinsically hard to model. Furthermore, many algorithms are fairly robust against misspecifications or poor performances of causal mechanisms.
在定义了我们的结构因果模型之后,我们现在可以更深入地了解哪些因素影响燃油消耗。首先,我们可以估计重量 -> mpg 和马力 -> mpg 连接的直接箭头强度。请注意,默认情况下,箭头强度方法衡量的是相对于方差的影响。
[4]:
arrow_strengths_mpg = gcm.arrow_strength(scm_mpg, target_node='mpg')
gcm.util.plot(scm_mpg.graph, causal_strengths=arrow_strengths_mpg)
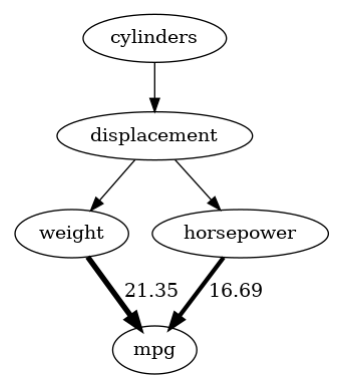
正如我们在此看到的那样,重量对 mpg 方差的影响远大于马力。
虽然知道直接父节点对我们感兴趣的节点有多大影响提供了一些有价值的见解,但重量和马力可能只是从其共同父节点继承信息。为了区分从父节点继承的信息和它们自身的贡献,我们应用 ICC 方法
[5]:
iccs_mpg = gcm.intrinsic_causal_influence(scm_mpg, target_node='mpg')
Evaluating set functions...: 100%|██████████| 32/32 [00:14<00:00, 2.20it/s]
为了更好地解释结果,我们将方差归因标准化为总和,以百分比表示。
[6]:
def convert_to_percentage(value_dictionary):
total_absolute_sum = np.sum([abs(v) for v in value_dictionary.values()])
return {k: abs(v) / total_absolute_sum * 100 for k, v in value_dictionary.items()}
[7]:
bar_plot(convert_to_percentage(iccs_mpg), ylabel='Variance contribution in %')
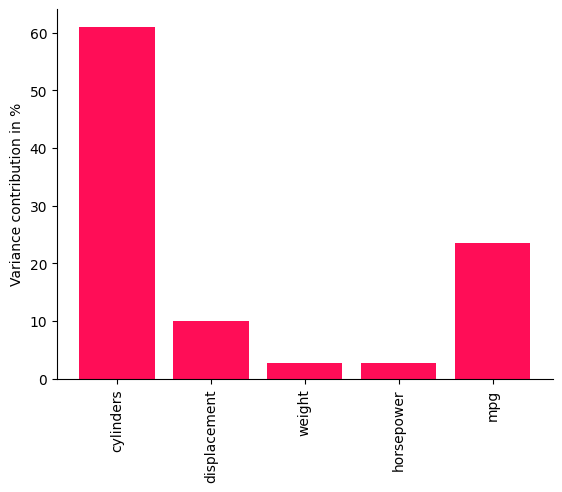
结果表明,汽缸数已经解释了燃油消耗的很大一部分,而像排量、马力和重量这样的中间节点主要从它们的父节点继承不确定性。这是因为,尽管重量和马力是更直接的 mpg 预测因素,但它们主要由排量和汽缸数决定。这为潜在的优化提供了一些有用的见解。正如我们从 mpg 本身的贡献中看到的那样,mpg 方差的大约 1/4 仍未被上述所有因素解释,这可能部分是由于模型不准确造成的。
虽然模型评估显示生成分布和观测分布之间的 KL 散度存在一些不准确性,但我们看到 ICC 仍然提供了非平凡的结果,即贡献在节点之间显著不同,并且并非所有内容都简单地归因于目标节点本身。
请注意,在 ICC 中估计对目标方差的贡献可以被视为结合了因果结构的非线性版本的 ANOVA。
河流流量的内在影响#
在下一个示例中,我们将查看在英格兰 Henthorn、New Jumbles Rock、Hodder Place、Whalley Weir 和 Samlesbury 的 5 个不同测量站在 15 分钟频率下记录的河流流量(\(m^3/s\))。在这里,更好地了解河流流量的行为有助于规划潜在的缓解措施以避免溢流。数据取自英国环境、食品和农村事务部网站。以下是河流地图
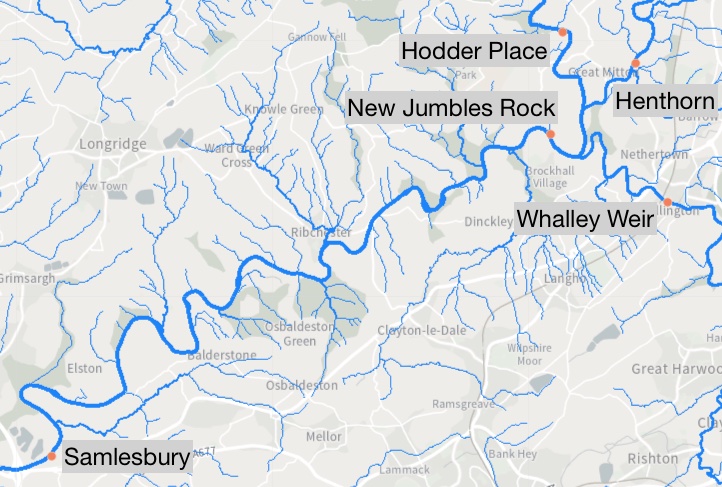
New Jumbles Rock 位于流经 Henthorn、Hodder Place 和 Whalley Weir 这三条河流的汇合处,New Jumbles Rock 流入 Samlesbury。流经某个测量站的水量肯定是上游下一个测量站观测到水量的一部分与沿途汇入河流的小溪和小河贡献的水量的混合物。这定义了我们的因果图为
[8]:
river_graph = nx.DiGraph([('Henthorn', 'New Jumbles Rock'),
('Hodder Place', 'New Jumbles Rock'),
('Whalley Weir', 'New Jumbles Rock'),
('New Jumbles Rock', 'Samlesbury')])
plot(river_graph)
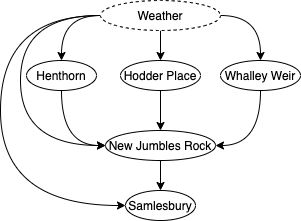
在这种情况下,我们对上游河流对 Samlesbury 河的因果影响感兴趣。与前面的例子类似,我们预计这些节点会受到(例如)天气等因素的严重混淆。也就是说,真实的图更可能是这样的
尽管如此,我们仍然期望 ICC 算法能够对 Samlesbury 河流流量的贡献提供一些见解,即使存在隐藏的混淆因素
[9]:
river_data = pd.read_csv("river.csv", index_col=False)
scm_river = gcm.StructuralCausalModel(river_graph)
gcm.auto.assign_causal_mechanisms(scm_river, river_data)
gcm.fit(scm_river, river_data)
iccs_river = gcm.intrinsic_causal_influence(scm_river, target_node='Samlesbury')
bar_plot(convert_to_percentage(iccs_river), ylabel='Variance contribution in %')
Fitting causal mechanism of node Samlesbury: 100%|██████████| 5/5 [00:00<00:00, 185.12it/s]
Evaluating set functions...: 100%|██████████| 32/32 [00:00<00:00, 297.94it/s]
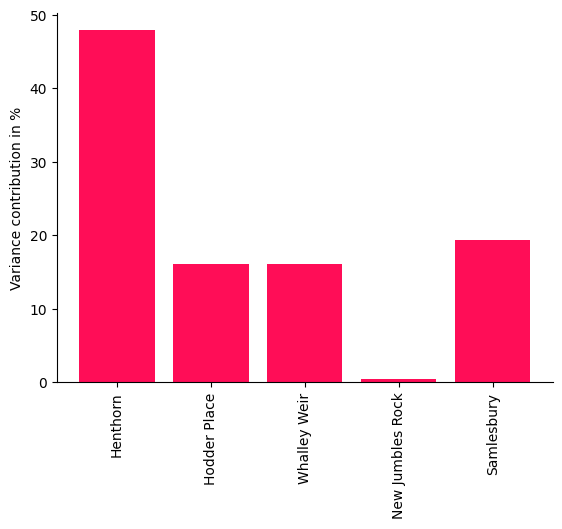
有趣的是,New Jumbles Rock 对 Samlesbury 的内在贡献很小,尽管对 New Jumbles Rock 的干预效应肯定会产生很大的影响。这说明 ICC 衡量的不是治疗效果强度意义上的影响,并在此指出 New Jumbles Rock 只是将流量传递给 Samlesbury。Samlesbury 本身的贡献代表了未捕获的(隐藏)因素。尽管我们可以预期节点会受到天气的严重混淆,但分析仍然提供了一些有趣的见解,这些见解只有通过仔细区分从父节点继承的影响和节点新添加的“信息”才能获得。